Break Them Down – Matrix Decomposition
We started simple, with a vector, and from that geometric idea we made our way through many linear algebra concepts. Some of them apply directly to real-world scenarios, like the dot product. Others are somewhat more abstract but still have great applicability to helping us deduce different concepts in linear algebra, like the eigenvectors. With the eigenvectors came a form of matrix decomposition, the eigendecomposition. We transformed a matrix into a product of three different matrices, namely two rotations and a scaling term. It is not a rule to decompose a matrix into three matrices. There are cases where we can decompose a matrix into a product of two others. However, in this book, we will cover two approaches to decomposition that happen to split a matrix into three different matrices: the eigendecomposition, which we just went through, and the single value decomposition, which will follow.
Before jumping into equations, let’s check with some visuals what happens when we rotate, stretch and rotate a vector again. Consider a generic vector  . Now to transform
. Now to transform  into
into  we first perform a rotation of 𝜃 degrees from
we first perform a rotation of 𝜃 degrees from  to
to  . The result is a vector called
. The result is a vector called  that will then be scaled σ units into
that will then be scaled σ units into  :
:

In other words, we know where we need to go, we are just breaking the path down into different stages. If A is a linear transformation, we can rewrite A as a product of rotations and stretches. For example, if you wish to rotate a vector by 𝜃 degrees, a matrix like the following will do the job:

For a scaling operation, a diagonal matrix will be able to help:

The first component of the vector gets scaled by a factor of σ1, while the second gets treated by σ2. So, a linear transformation will take any vector from the vector space, rotate it by the same angle, and then stretch it by some amount. Let’s now focus our attention on a particular case, a circle.
We can define a pair of vectors to form a set of axes in the circle, and, as with the Cartesian plane, let’s make them perpendicular:

The vectors  and
and  that form this axes are also of the length of the circle’s radius. Maintaining the perpendicular orientation of these vectors after transforming them means that we will have a new axes in the newly transformed space. Therefore, it will probably be possible to derive the characteristics of these newly transformed vectors as a function of rotations and stretches. If we stretch and rotate a circle, we end up with an ellipse, with
that form this axes are also of the length of the circle’s radius. Maintaining the perpendicular orientation of these vectors after transforming them means that we will have a new axes in the newly transformed space. Therefore, it will probably be possible to derive the characteristics of these newly transformed vectors as a function of rotations and stretches. If we stretch and rotate a circle, we end up with an ellipse, with  and
and  now constituting the minor and major axes of this newly mapped elliptical shape. In addition, if we define the norm of the vectors that compose the original axes to be one, perhaps we could understand how much they get scaled after a transformation, if we also introduce some parameters to reflect it. We have set up a good scenario in which to decompose a matrix into rotations and a stretch by doing these two things. What we’re missing is a linear transformation that not only guarantees that the angle between the vectors remains the same, but also preserves the magnitude of their norms. There is a type of matrix that always allows a transformation with these features to occur, namely the orthonormal matrix. But what are these orthonormal matrices? An orthonormal matrix, by definition, is a matrix whose columns are orthonormal vectors, meaning that the angle between them is 90 degrees and each of the vectors have a norm or length equal to one. These types of matrices have some excellent properties that make computations easier and very intuitive. Consider an example of a 2 × 2 orthonormal matrix. Let’s call it Q: not Mr Q, just Q:
now constituting the minor and major axes of this newly mapped elliptical shape. In addition, if we define the norm of the vectors that compose the original axes to be one, perhaps we could understand how much they get scaled after a transformation, if we also introduce some parameters to reflect it. We have set up a good scenario in which to decompose a matrix into rotations and a stretch by doing these two things. What we’re missing is a linear transformation that not only guarantees that the angle between the vectors remains the same, but also preserves the magnitude of their norms. There is a type of matrix that always allows a transformation with these features to occur, namely the orthonormal matrix. But what are these orthonormal matrices? An orthonormal matrix, by definition, is a matrix whose columns are orthonormal vectors, meaning that the angle between them is 90 degrees and each of the vectors have a norm or length equal to one. These types of matrices have some excellent properties that make computations easier and very intuitive. Consider an example of a 2 × 2 orthonormal matrix. Let’s call it Q: not Mr Q, just Q:

For the matrix to be orthonormal, each column vector has to be of length one and they need to be at 90 degrees to one another, which is the same as having a dot product equal to zero. Since we’re still getting to know each other, and if you aren’t confident that my police record is clean, then there is a case to say that our trust bond is still under development. So let’s check the norms of those bad boys:

It follows that:


And the dot product is:

Okay, it seems we have an orthonormal basis; now I would like to do an experiment. The name orthonormal is the perfect setup for an adolescence defined by bullying. However, not everything is terrible. There is something else happening with these matrices. Multiplying QT by Q will create a relationship that we can leverage. We know that, for matrix multiplication, we use the dot product of the columns by the rows; if the vectors are orthogonal, some of those entries will be 0. Let’s transpose Q and see what the deal is with this:

And:

This is a result that is definitely worth paying attention to as we can build a connection between the inverse and the transpose matrices. But first, let’s see if this happens for any size of matrix. For example, say that we have Q, which is an orthonormal matrix, but this time it has n vectors  :
:

So  ,…,
,…, are all orthonormal vectors which form the columns of Q. The transpose of Q will have this shape:
are all orthonormal vectors which form the columns of Q. The transpose of Q will have this shape:

It follows that, multiplying QT with Q:

The columns of Q are orthogonal vectors, so the dot products among them are 0. Therefore, if QT has the same vectors as Q, most of the dot products will also have zero value. The exception is when we take the dot product of the vector by itself, which means that all of the non-zero elements will be on the diagonal. Adding to this, we also know that the vectors  have a norm equal to one, so the resultant matrix will be the identity I. Let’s bring back the transformation of a circle into an ellipse, but this time, let’s define
have a norm equal to one, so the resultant matrix will be the identity I. Let’s bring back the transformation of a circle into an ellipse, but this time, let’s define  and
and  in such a way that we can quantify how much they are scaled by A. The vectors
in such a way that we can quantify how much they are scaled by A. The vectors  and
and  , are scaled and rotated by A. We know that the angle between them will not change, as we’re using an orthonormal matrix to perform the mapping, but how the vectors will scale at this point is still unknown. We can solve that by defining two unit vectors,
, are scaled and rotated by A. We know that the angle between them will not change, as we’re using an orthonormal matrix to perform the mapping, but how the vectors will scale at this point is still unknown. We can solve that by defining two unit vectors,  and
and  , that will tell us the direction of the new set of axes formed by
, that will tell us the direction of the new set of axes formed by  and
and  . Because
. Because  and
and  were defined with a norm that requires a length of 1, we can quantify the change in length that is a consequence of applying A. To do so, we can multiply them by a scalar, for example, σ1 and σ2. So the new axes will be:
were defined with a norm that requires a length of 1, we can quantify the change in length that is a consequence of applying A. To do so, we can multiply them by a scalar, for example, σ1 and σ2. So the new axes will be:

We transformed a circle into an ellipse, and consequently, the vectors  ’s into
’s into  ’s. Then we decided to find a new way to represent the transformed version of these same
’s. Then we decided to find a new way to represent the transformed version of these same  ’s. This allowed us to define these vectors by the multiplication of a scalar σ with a vector
’s. This allowed us to define these vectors by the multiplication of a scalar σ with a vector  . There are names for all of these new appearing players. The
. There are names for all of these new appearing players. The  ’s are the principal axes and the σ’s the single values:
’s are the principal axes and the σ’s the single values:

A transformation of  by the matrix A can then be represented as:
by the matrix A can then be represented as:

The only thing we did was to replace  with A ⋅
with A ⋅ . This equation reflects everything we have been discussing up until this point, a transformation of
. This equation reflects everything we have been discussing up until this point, a transformation of  enabled by A is equal to a scaled rotation of an orthonormal vector
enabled by A is equal to a scaled rotation of an orthonormal vector  . The beauty of linear algebra is the ease with which we can move into higher dimensions. Our example was a circle, which is in a vector space of size two. We selected this space so that we could visualise these concepts. In reality, if you apply any matrix decomposition, there is a significant chance that you will be working with larger space sizes. One of the applications of matrix decomposition is to reduce dimensions, so logically these matrices will have higher dimensionality. An explanation of this concept and a few others will follow shortly. We just need an equation, and we are halfway there. If you recall, the manner in which we handled earlier concepts was to define a starting case and then to accommodate a generalised solution for n. For all of the vectors, we can have an equation like:
. The beauty of linear algebra is the ease with which we can move into higher dimensions. Our example was a circle, which is in a vector space of size two. We selected this space so that we could visualise these concepts. In reality, if you apply any matrix decomposition, there is a significant chance that you will be working with larger space sizes. One of the applications of matrix decomposition is to reduce dimensions, so logically these matrices will have higher dimensionality. An explanation of this concept and a few others will follow shortly. We just need an equation, and we are halfway there. If you recall, the manner in which we handled earlier concepts was to define a starting case and then to accommodate a generalised solution for n. For all of the vectors, we can have an equation like:
 |
(5.1) |
With:

Algebraically, we can express it like:

This is simply a different way of writing equation 5.1. Finally, we can use the following notation:

Greatness would come if A was by itself in this equation. In mathematics, loneliness is not necessarily a bad thing. We need to represent A via a product of three matrices, namely two rotations and a scaling term. But, we need A to be isolated, which we can achieve by multiplying each of the sides of the equation by the inverse of V :

And because V is orthonormal, the matrix V −1 = V T:
 |
(5.2) |
Where:
- U represents a rotation.
- Σ is the scaling matrix.
- V T is another rotation.
The image below is a representation of the entire transformation and decomposition process:

The vector’s basis, or the axes, are rotated into a new set of orthonormal vectors via V T. The resulting set of vectors is then scaled by the matrix Σ before being rotated by U to produce the desired version of the transformed vectors. Now would be a good moment to pause and look into the dimensionalities of the matrices in equation 5.2. The matrix U is so named because its columns are all the  ’s and these are all in ℝm. Meanwhile V T has rows represented by the
’s and these are all in ℝm. Meanwhile V T has rows represented by the  ’s and these fellows are in ℝn. We can verify this by looking into, for example, the equation that we defined previously:
’s and these fellows are in ℝn. We can verify this by looking into, for example, the equation that we defined previously:

If A is of size m × n, the only way for that left-hand multiplication, Am×n ⋅ to be possible is if
to be possible is if  is a vector with dimensions n × 1. The result of this will be a matrix of size m × 1:
is a vector with dimensions n × 1. The result of this will be a matrix of size m × 1:

Computing A. results in:
results in:

If σ1 is a scalar, it will have no effect on the dimensions of  after we multiply the two together. So, if the element on the left side of the equation has dimensions of m× 1, then
after we multiply the two together. So, if the element on the left side of the equation has dimensions of m× 1, then  must also have dimensions of m × 1, otherwise we can’t verify the equality above. Cool, so it follows that v1,…,vr ∈ ℝn and u1,…,ur ∈ ℝm, meaning U is related to the columns in A and V is related to the rows. If we now consider the four subspaces that we introduced previously, we can define the column space and the row space of A as functions of U and V , such that:
must also have dimensions of m × 1, otherwise we can’t verify the equality above. Cool, so it follows that v1,…,vr ∈ ℝn and u1,…,ur ∈ ℝm, meaning U is related to the columns in A and V is related to the rows. If we now consider the four subspaces that we introduced previously, we can define the column space and the row space of A as functions of U and V , such that:
- The set u1,…,ur is a basis, in fact an orthonormal basis for the column space of A.
- The set v1,…,vr is a orthonormal basis for the row space of A.
We have gathered some knowledge about all of the vectors  ’s and all of the vectors
’s and all of the vectors  ’s, but we still don’t know what r can possibly be. The matrix Σ is a diagonal matrix of size r × r. Each column has only one non-zero value, and the position of this element varies from column to column. The fact that it is never at the same column index makes all the columns of Σ linearly independent. Consequently, Σ has a rank value of r. Going back to U, we know that it forms an orthonormal basis, and if this particular matrix has r columns, the rank of this matrix is also r. Multiplying U by Σ results in the matrix UΣ, which will also have rank r as Σ will only scale U. Therefore, the columns will remain linear and independent. For simplicity, let’s refer to UΣ as U∗. We now need to understand what happens when we multiply U∗ by V T; we still don’t know how to relate the magnitude r to A. Okay, let’s consider a generic column
’s, but we still don’t know what r can possibly be. The matrix Σ is a diagonal matrix of size r × r. Each column has only one non-zero value, and the position of this element varies from column to column. The fact that it is never at the same column index makes all the columns of Σ linearly independent. Consequently, Σ has a rank value of r. Going back to U, we know that it forms an orthonormal basis, and if this particular matrix has r columns, the rank of this matrix is also r. Multiplying U by Σ results in the matrix UΣ, which will also have rank r as Σ will only scale U. Therefore, the columns will remain linear and independent. For simplicity, let’s refer to UΣ as U∗. We now need to understand what happens when we multiply U∗ by V T; we still don’t know how to relate the magnitude r to A. Okay, let’s consider a generic column  that belongs to the column space of U∗V T such that:
that belongs to the column space of U∗V T such that:

So, by considering a column  , we can take some vector
, we can take some vector  ∈ ℝn and transform this into
∈ ℝn and transform this into  via U∗V T:
via U∗V T:
 |
(5.3) |
If we rewrite equation 5.3 to:

This indicates that  is also in the columns of U, which means that:
is also in the columns of U, which means that:
 |
(5.4) |
If  is in the column space of U, then we must also have a vector
is in the column space of U, then we must also have a vector  such that
such that  ∈ ℝr, which when transformed by U∗, results in
∈ ℝr, which when transformed by U∗, results in  . If you recall, we have demonstrated that V T ⋅ V is equal to the identity I. We can ”squeeze” this into equation 5.4:
. If you recall, we have demonstrated that V T ⋅ V is equal to the identity I. We can ”squeeze” this into equation 5.4:

We can replace Ir by V T.V :

Well, this means that this geezer (yes I lived in England and loved it!)  ∈ Col
∈ Col . Before we got into this crazy sequence of equations, we had concluded that the rank of U was r, and now we have just shown that Col
. Before we got into this crazy sequence of equations, we had concluded that the rank of U was r, and now we have just shown that Col = Col
= Col so:
so:

If we wish to calculate the rank of A, we can do so using the following expression:

The conclusion is that the right side of the equation is of rank r, so we have:

Now we are in a state where we can understand the dimensions of the four subspaces of A. So far, we have defined two: the row space with size r, and the column space with the same dimension. The only subspaces that still haven’t shown up to the party are the nullspace and the left nullspace. And believe me, we do need to know the sizes of these good fellows. For that, we can use the rank-nullity theorem. Let’s start with the nullspace. We know that:

So:

The nullspace of A has dimension n − r and the basis for it are the vectors vr+1,…,vn. The left nullspace is of size m − r because:

And its basis is ur+1,…,um. These are important results, and I will explain why, but first I would like to box them up so we can store them all in one place:
- u1,…,ur is an orthonormal basis for the column space and has dimensions of r.
- ur+1,…,um is an orthonormal basis for the left nullspace and has dimensions of m − r.
- v1,…,vr is an orthonormal basis for the row space and has dimensions of r
- vr+1,…,vm is an orthonormal basis for the nullspace and has dimensions of n − r
Let’s bring back the equation that reflects the decomposition of A:
 |
(5.5) |
If we take a closer look at the dimensions of each matrix, we can see that we are missing the vectors for both the nullspace and left nullspace in matrices V and U. Equation 5.5 represents the reduced version of the SVD. You may also remember this technique as the Single Value Decomposition that we spoke about earlier, but all the cool kids prefer to use its street name.
5.1 Me, Myself and I – The Single Value Decomposition (SVD)
The reduced form of this decomposition can be represented by:

Where r is the rank of matrix A as we proved earlier. A visual representation of the reduced single value decomposition is always useful.

If we wish to have a full version of the singular value decomposition (SVD), we must incorporate the left nullspace in the matrix Ur and the nullspace in the matrix V r. As these vectors are all orthogonal, we can do this without causing any problems with the orthonormality of Ur and V r. In the matrix Σ we will include any single value that has a value of zero or, if necessary, add a row of zeros to ensure it’s of size n × n. We know the rank of U and the dimension of the nullspace, as these are r and m − r respectively. These dimensions mean that U will be of size m × m. Similarly, V will be of size n × n because the nullspace has dimensions of n − r. So, the equation of the full single value decomposition is very similar to that of the reduced version:
 |
(5.6) |
Graphically, this is what the full SVD looks like:

There is no information loss between the complete SVD and the reduced version of the same algorithm. The difference is that the reduced version is cheaper to compute. The SVD is probably the most potent decomposition from linear algebra that you can apply in machine learning. The algorithm has many applications, including recommendation systems, dimensionality reduction, creating latent variables, and computer vision. It is a versatile technique, and that is why it is crucial that we fully understand it.
The only thing we’re missing, and it’s probably one of the most essential, is an understanding of how to compute V , U, and Σ. We already did the visual work, so the central concept of this technique is covered in the plots. We defined the single value decomposition in such a way that the rotation matrices must be orthonormal. This is a constraint that will mean that the matrices from which we want to obtain a decomposition have to have some kind of properties that ensure orthogonality after some transformation. There is a type of matrix that will have something to do with orthogonality, the symmetrical ones. If a matrix is symmetrical, not only are the eigenvalues real but also the eigenvectors are orthogonal. Perhaps this is a good starting point, so let’s explore it.
The definition of a symmetric matrix is straightforward. A symmetric matrix is such that A = AT. Visually, it will be a matrix in which elements at the top of the diagonal will be equal to those at the bottom of the diagonal. Think of the diagonal as a mirror:

If you switch the rows with the columns to get the transpose, you will end up with the same matrix. The only caveat now is that, in the SVD equation, A does not have to be a square matrix, let alone symmetrical. So, the conclusion is that the SVD is a load of crap and I am a liar… or… or it means that there is a way we a can transform A into a square symmetrical matrix. Let’s start by thinking about the dimensions. If A is of size m × n, then the only way to have a square matrix is if we multiply A by a matrix of size n × m. Okay, so which matrix can we define to achieve such a thing? Let’s bring back the SVD equation:
 |
(5.7) |
At this point, we only know A from equation 5.7. So randomly selecting a matrix of the correct size to multiply by A seems like a bad idea (right?!). After all the work we’ve invested into defining orthonormal transformations and scaling factors to keep track of movement in space, throwing in something random at this stage won’t work. Like any subject politicians try to convince us about, we have two options to choose, meaning that if we select one, the other is automatically wrong.
No need to think about anything! It is either A or AT. Picking A won’t work because this matrix can be rectangular and therefore we can’t multiply it by itself. So AT is what remains. Remember that the multiplication of two matrices is a composition of scaled rotations achieved by dot products between rows and columns. A and AT have the same vectors for entries, and the only difference is that they’re displayed differently. So, we can guarantee that the matrix will be square, but we are still unsure if it will be symmetrical. Consider an example of matrix A defined as such, and let’s check what happens when we perform the dot product between the rows and columns with the same colour:
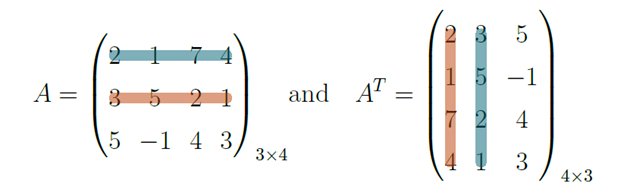
Let’s say B is the resultant matrix from the multiplication of A by AT. B has dimensions of 3 × 3. The element b1,2 is the dot product between the vectors highlighted in blue, and the element b2,1 is the result of the dot product between the orange highlighted vectors. The result of these dot products is equal. The vectors are the same in the two operations, therefore b1,2 = b2,1. This result will occur for every element of these matrices except for the diagonal since the diagonal comes after the dot product between two equal vectors. The first step of getting the three components of the SVD for the equation, A = U ⋅ Σ ⋅ V T, is done: now we will multiply both sides by AT:

There are a lot of T′s in that equation, but as we have diagonal and orthonormal matrices, we can make the equation look a little better. It follows that (A ⋅ B)T = BT ⋅ AT, and if we apply this to the equation, it becomes:

Okay, so I have two pieces of information about these matrices that will allow some further simplification:
- That guy, Σ is a scaling matrix and therefore a diagonal matrix. The only non-zero entries are on the diagonal, and therefore the transpose is equal to the original matrix, i.e, Σ = ΣT.
- The matrix U is orthonormal, and it was proved earlier that the transpose of matrices with this property are equal to the inverse: U−1 = UT.
It follows that:

And the multiplication of UT by U will result in the identity matrix such that:

Which is equivalent to:
 |
(5.8) |
We are getting closer to a way to compute V , which is not bad, but we still don’t know how to get Σ or U. The problem is that we are depending on Σ to compute V . Our solution is to fetch something that we learned earlier and then to apply it to see if we can make some progress. Looking at 5.8, we know that Σ2 is full of scalars on its diagonal, and, just to satisfy your curiosity, they are all positive. The only equation I can recall that we’ve covered lately with scalars on the diagonal of a matrix is the one we used to compute eigenvalues. Let’s see if something can be done with this, but allow me to refresh your memory:
 |
(5.9) |
Let’s try to make equation 5.8 look similar to equation 5.9. For that, we need a vector or another matrix on the right side. We know that V T = V −1 and we can leverage this by multiplying 5.8 by V on both sides:

And, it follows that:
 |
(5.10) |
Take a good look at this bad boy. Sometimes mathematics is almost like an illusion. Let’s say that A is equal to AT ⋅ A, then V takes the place of  , and the matrix which just has elements on its diagonal replaces λ. This means we have created an eigenvalue problem where Σ is an eigenvalue matrix. Okay, we can work with this! So, we have found a way to compute Σ and V , but we still need U. I multiplied A on the left by AT, and all the U’s went for a walk: they disappeared from the equation. So perhaps I can multiply A by AT, but this time on the right. And who will be taking a walk this time? That’s right; it will be the V ’s. Let’s check:
, and the matrix which just has elements on its diagonal replaces λ. This means we have created an eigenvalue problem where Σ is an eigenvalue matrix. Okay, we can work with this! So, we have found a way to compute Σ and V , but we still need U. I multiplied A on the left by AT, and all the U’s went for a walk: they disappeared from the equation. So perhaps I can multiply A by AT, but this time on the right. And who will be taking a walk this time? That’s right; it will be the V ’s. Let’s check:

I think you can see where this is going. We do the same as we did before when we computed the equation by multiplying A by AT on the right:

Then:

And multiplying by U on both sides, it follows that:
 |
(5.11) |
We end up with a similar eigenvalue problem, and Σ happens to be the same for the two equations. Solving these eigenvalue equations will give us U and V . And as A ⋅ AT is a square symmetric matrix, its eigenvalues will all be distinct and real; when squared rooted, they will give us the single values. The eigenvectors that form U and V will be orthogonal, allowing any vectors transformed by these matrices to preserve the angles between them. If we recall the ”requirements” for all those transformations when done graphically, this was exactly it. There is only one more thing, the matrix Σ which contains the single values will be sorted such that, σ1 ≥ σ2 ≥ … ≥ σn.
I believe that the computation of such matrices will become solidified for you with a simple numerical example. Consider the matrix A defined as:
 |
(5.12) |
The first step will be to compute A.AT and AT.A:


To compute the matrix U, we need to solve the eigen problem in equation 5.11, let’s start:


This results in λ1 = 9 and λ2 = 1. Now we need the eigenvectors:

For the value of λ1 = 9 it follows that:

That, in turn is equivalent to:

So we have u11 = 1 and u12 = 1 meaning that  = (1, 1)T. Remember that U is an orthonormal basis. Its vectors must have length 1. We need to normalise them. Let’s start by calculating
= (1, 1)T. Remember that U is an orthonormal basis. Its vectors must have length 1. We need to normalise them. Let’s start by calculating  ’s norm:
’s norm:

So u1 is such that:

Doing the same for the eigen value, λ = 1:

With:

In this case we have found that u211 = −1 and u22 = 1, meaning that  = (−1, 1)T. The norm of
= (−1, 1)T. The norm of  is also
is also  , therefore the normalised form of
, therefore the normalised form of  is:
is:

Perfect, so we have computed the matrix U. It is an orthonormal matrix because the eigenvectors have been normalized and AT.A is a symmetrical matrix. Its eigenvectors are therefore orthogonal:

Next, we need the eigenvalues of A ⋅ AT:

![= (1 − λ) [(8 − λ )(1 − λ) − 4] − 4(1 − λ ))](https://static.packt-cdn.com/products/9781836208952/graphics/beforeMachineLearningVol1LinearAlgebraV2911x.svg)



Thus, it follows that, λ1 = 9, λ2 = 1 and λ3 = 0. And to define V , we are just missing the normalised eigenvector for each eigenvalue:
For λ1 = 9:




For  we have the vector (1,−4, 1)T, and its norm is given by:
we have the vector (1,−4, 1)T, and its norm is given by:

This makes the normalised version of  equal to:
equal to:

Carrying on with the eigenvalue calculations, for λ2 = 1, we have the following:



For  we have the vector
we have the vector  = (−1, 0, 1)T and the norm of
= (−1, 0, 1)T and the norm of  :
:

So the normalised version of  is:
is:

Finally,  , where λ3 = 0, is:
, where λ3 = 0, is:



For  we have the vector (2, 1, 2)T, and its norm is equal to:
we have the vector (2, 1, 2)T, and its norm is equal to:

Which makes the normalised version of  :
:

The only matrix we’re missing is Σ, but in fact, we have all the information we need to populate this matrix because the σ´s are the square root of the eigenvalues, so σi =  :
:

That was quite a bit of work, but thankfully we have computers, so it’s not necessary to do this every time you wish to apply this algorithm. All the same, I believe that going over a simple example is always helpful to solidify your understanding of the algorithm in full. There’s also the added bonus that these three matrices will allow you to do several things, so understanding how they are derived and what constitutes each is a great piece of knowledge to add to your arsenal. Finally, we can represent A as:

We should check that I’m not just talking nonsense or making shit up! Every time I use a sauna, I think about something similar. What if the guy that invented this concept of a room that gets really warm and steamy was just messing with us, and now everybody thinks it’s great? To avoid this kind of train of thought, let’s multiply those three matrices:


In the example we’ve just covered, we computed the full version of the single value decomposition, which implies that both the null and left nullspaces are part of the matrices V T and U. Previously, we concluded that the nullspace would be in the rows of matrix V T. The equation that allowed us to compute the eigenvector for an eigenvalue of 0 is the same as the one we defined for calculating the nullspace: A = 0. But what about the left nullspace? Well, as a result of the decomposition, I can tell you that this is (0, 0), but let’s verify this. We know that the left null is:
= 0. But what about the left nullspace? Well, as a result of the decomposition, I can tell you that this is (0, 0), but let’s verify this. We know that the left null is:

If we solve that system, we end up with:

As expected, the left nullspace is the vector (0,0), and its dimension is zero. Therefore, if we wish to use the reduced decomposition version, we need to remove the nullspace from the matrix V and adjust the matrix Σ accordingly:

This is a lot of mathematical contortions: rotations, stretches, and equations. Next, I’ll present a small example of a real-life scenario where the decomposition of matrices is an excellent way to extract practical, valuable information. But before that, I would like to point out that the single value decomposition includes nearly everything we’ve learned so far in this book: it is thus an excellent way for us to make a self diagnosis on the solidity of our understanding of the linear algebra concepts that have been presented.
On the theme of applicability, I believe that there are three main areas in which to use SVD. The first one, my favourite, is the creation of latent variables. These are hidden relationships that exist within data. An elementary example would be for me to predict if it was raining or not without information on the weather report. For instance, I could do so by observing whether your jacket is wet or not when you arrive home.
I can also discuss an example where I produced great results when trying to predict outcomes related to human emotions, all by analysing hidden variables. It’s hard to have a data set containing a happiness feature from the get-go, but perhaps these can be extracted from the data as a latent variable. With SVD, these variables are present in the matrices U and V . These types of variables also allow us to reduce the dimensionality of a data set.
Secondly, the singular value decomposition allows us to make an excellent approximation of a matrix. An approximation can be helpful for two purposes: we can remove data or information that is not relevant to what we are trying to do, making a prediction, for example; and we can condense this approximation to a few vectors and scalars, which can be extremely useful for storing data more efficiently.
Lastly, you can build a simple recommendation system. As this is linear algebra and the focus of this book is to visualise concepts in order to understand how they work, I will illustrate all of the applications described above in a real-world example. Let’s consider a matrix containing item ratings by users. Each user can rate a given item with an integer score that ranges from 1 to 5. A matrix is an excellent choice to represent these dynamics. Let’s say we have six items and we’ll say they are songs. Yep, six different songs that users have rated according to their preferences, and our sample has eight users. Now yes, I know, this is a tiny, tiny data sample. And yes, you are likely to encounter far bigger data sets when the time comes to apply a single value decomposition, but for illustration purposes, this is enough. Let’s then construct this matrix:
 |
(5.13) |
The matrix A is defined by 5.13. Now we need to decompose this into UΣV T, but this time I will use a computer to calculate the full version of the SVD. A will then be decomposed into:

It follows that the matrix U has the following entries:

For a full version of V , we have:

Finally, Σ is equal to:

The first thing to notice is that these are three big-ass matrices! I don’t know if it is the coffee I just drank or the size of these bad boys, but this is giving me anxiety! While there is a lot of information to deal with, we’ll take it step by step. We can deduce the values for Σ via an eigenvalues problem, meaning that if we multiply U and Σ, we will end up with the projections of all the vectors  ’s into the newly transformed axes; remember that each of the
’s into the newly transformed axes; remember that each of the  vectors are orthonormal. And, if we constructed Σ in a way such that σ1 ≥ σ2 ≥ … ≥ σn, then it makes sense to assume that the highest sigma value will be the furthest point projection. This will therefore represent the biggest spread and hence the highest variance. Let’s define a measure of energy as:
vectors are orthonormal. And, if we constructed Σ in a way such that σ1 ≥ σ2 ≥ … ≥ σn, then it makes sense to assume that the highest sigma value will be the furthest point projection. This will therefore represent the biggest spread and hence the highest variance. Let’s define a measure of energy as:

We can then select how much of it to use. Say for example, that we need around 95% of this energy, it then follows that the total energy for our system is equal to:

If we wish to use that percentage value, we can remove the values of σ4, σ5, and σ6. Well now, this means two things: we can replace these sigma values with zeroes, which will result in a trio of new U, Σ and V T matrices, and consequently a new version of A; and if σ4, σ5, and σ6 become zero, then the matrix Σ has the following format:

Essentially, we are just keeping the information represented by the first three singular values, meaning that we will reduce everything to three dimensions, which in machine learning is called dimensionality reduction. We get rid of some information to make our lives easier. In this example, I wish to represent these relationships visually, as the new contexts are very important. These are the so-called latent variables, which define those cunningly hidden relationships in data.
The interpretation of these variables is up to you and it’s usually linked to the nature of the problem that you are dealing with. In this case, the context is the music genre. I should point out that there are other applications for dimensionality reduction. For example, clustering algorithms tend to work better in lower dimensionality spaces. Working with a model with all of the available information does not guarantee good results. But, often, if we remove some noise we will improve the capacity of the model to learn.
What results from this reduction is a new version of the three amigos U, Σ ,and V T, which we call the truncated single value decomposition. This version of the decomposition is represented by:

In this case, t is the number of selected singular values, which for this particular example is:

For the truncated version of U, Ut, we can remove the vectors  4 to
4 to  8 because we replaced σ4 to σ6 with zero. The truncated version of U has the following shape and entries:
8 because we replaced σ4 to σ6 with zero. The truncated version of U has the following shape and entries:
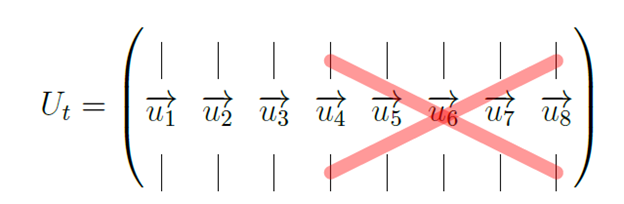
We can apply the same logic to the matrix Σ because the columns will just be zeros after we replace the single values with zeros. We can therefore remove them:
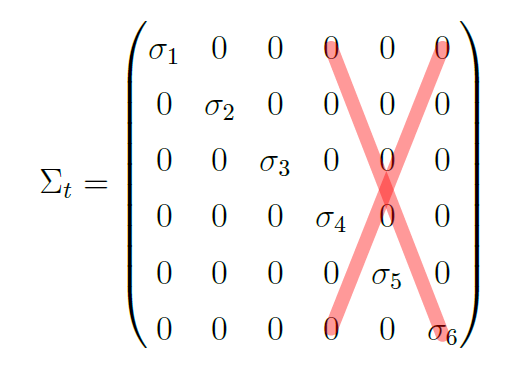
And V T will follow:
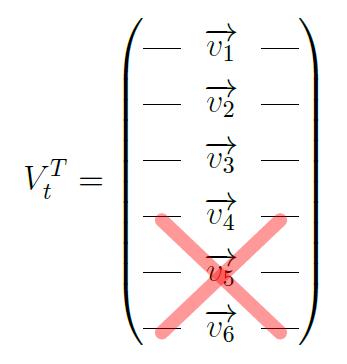
So, Ut is a matrix of users by context:

In this example, the matrix A contains information about user ratings for different songs, so perhaps one interpretation of this context’s variables could be the song genre: hip hop, jazz, etc. This is just one possibility as the interpretation for this particular type of variable is dependent on the business problem at hand. Now we have another way of relating users, as we go from song ratings to song genre, and we also have a smaller matrix, the matrix U. Because we were able to reduce the dimensions by only selecting the three highest singular values, we can plot this thus:

We can identify some patterns in this plot in terms of similarity of taste based on music genre. Specifically, user0 and user7 seem to have similar tastes and the same seems to be evident with the pairs of user2,user5 and user6,user3. It is true that, in this example, you could identify these relationships by simply looking at the matrix A. Still, your matrix will probably have a much higher dimensionality in a real-world situation, and the number of columns will be much larger. With this information, we could segment users based on their music tastes.
An excellent way to do this would be to apply a clustering algorithm to matrix U, as this would return user cohorts who share song preferences. The reason we only use U is that this a fairly simple example and the singular values are not that distinct. In case of higher dimensionalities with singular values that differ more, it would be better to use UΣ. The immediate advantages of this include being able to work in a smaller space. Certain algorithms will perform well in these types of space, and it will be computationally cheaper to train them. I won’t assume that these concepts are familiar to you, so I will briefly explain. A clustering algorithm has the goal of grouping data that shares identical features, in this case, users that are similar to each other. If you were to run it on matrix U, the outcome would probably be comparable to what I described above. The result would be five groups:

Now, to train a classifier. Hold on one moment; those are some seriously fancy words that circulate in every meeting room and blog on the internet… if you are completely new to machine learning, “training” means to find a configuration for a set number of parameters that characterise a model or an equation.
Okay, back to the point, to train this you need a particular dataset which has labels. These labels are like an outcome that the features will characterise. So, for example, the metrics of the data can be a set of measurements of an engine, and the label can be whether or not the motor was working, a zero for not working and a one otherwise. An algorithm will then accommodate a set of parameters so that those two classes can be separated. For simplicity, say that our model is a line. The equation for this shape is y = mx + b. We want to build our model in a way that separates our data into two groups. We aim to have as many zeros below the line as possible, and the maximum number of ones above it. The only thing we can control with that line are the parameters m and b.
So, we will try to find a configuration that can separate our data in the best way possible, and for that, we will be using the provided data set. For example, we can start by randomly drawing a line in space. Our goal is to have all of the one labels above the line and all of the zero labels below the line. As we randomly selected values for m and b, it’s likely that these values will not be the best right away but how can we verify this?
Well, this is why we need the labels. We can count the number of ones that are above the line and the quantity of zeros that are below the line. We can then tweak the values of m and b to see if this result has improved, meaning that we have more ones above and more zeros below the line respectively.

The algorithm I’ve just described will look randomly for solutions; these types of algorithms are generally called “greedy”. It will not be a good heuristic if we don’t tell it where to look for the best solutions. But this is just an example; if you are curious, one way of providing an algorithm with information on where to move is via derivatives.
Such concepts will be part of volume two, which will be a book dedicated to calculus. The point here is to understand that, in order to train a model, we need to get a configuration of parameters for an equation (or several) that allows us to achieve our goal as well as we can. So if we have a dataset with labels, there are times when we can better separate data by using latent variables. As we are reducing the number of columns going from A to U, the process is called “dimensionality reduction” in machine learning. This is because we have moved from a higher dimensional space to a lower one, thus reducing the complexity of our problem. Going back to the example of SVD, we haven’t looked into the information in matrix V . This particular matrix happens to be an interesting one because it will provide us with the relationship between genre and songs:

Similarly, we can plot this to visually check for closer relationships between songs rather than users:

We can see that song0, song3 and song4 seem to be of the same genre, while song5, is probably from a different genre. Finally, song2 and song1 seem to be from the same or a similar genre.
So, we have identified a use case for the single value decomposition. By computing U and V T, we found new hidden relationships in the data, represented by the latent variables. We also learned that we could leverage these relationships to train algorithms. Just by itself, this is extremely useful, but we can do more with this decomposition.
If you recall, a matrix is a linear transformation. When you multiply a vector by a matrix, you will be moving these vectors, a movement that can take place within the same space or between different spaces. In this example, we have two matrices that we can use to transform vectors. These are the matrices U and V T. Let’s look into V T. This matrix has context for columns, which for us is the same as music genre, whereas the rows are songs. So we went from users and song ratings, via matrix A, into a new space, V T which relates songs by genre. We can create a vector with user ratings and transform it with V T to understand which genre this particular user is most interested in. Let’s check this with an example. Say that we have user8 with the following ratings:
![user8 = [5, 0, 0,0, 0,0 ]](https://static.packt-cdn.com/products/9781836208952/graphics/beforeMachineLearningVol1LinearAlgebraV2972x.svg)
If we now transform the user8 vector via the matrix V , we will transform user8 into a space of songs by context:
![( ) | 0.35 − 0.46 0.54 | | | || − 0.27 0.45 − 0.30 || | − 0.26 − 0.19 − 0.19 | | | [5,0, 0,0, 0, 0] ⋅ || − 0.46 0.54 0.00 || | | || − 0.35 0.27 0.60 || | | | − 0.62 − 0.41 − 0.44 | ( )](https://static.packt-cdn.com/products/9781836208952/graphics/beforeMachineLearningVol1LinearAlgebraV2973x.svg)
This results in the following vector:
![[− 1.79, − 2.30, 2.74 ]](https://static.packt-cdn.com/products/9781836208952/graphics/beforeMachineLearningVol1LinearAlgebraV2974x.svg)
That new vector shows the new context values or the music genres for user8. With this information, you can, for example, make recommendations. So, you will show this user music from the context or genre 3. It will also be possible to make a user-to-user recommendation, which recommends music from a user with a preferred genre that is similar to user8. For this, we need a measure of similarity. Let’s refresh our memory and look at one of the formulas we derived when studying the dot product. If you recall, there was a way to compute this metric by making use of angles:
 |
(5.14) |
In this case 𝜃 is the angle between the vectors  and
and  . We can manipulate equation 5.14 and leave it as:
. We can manipulate equation 5.14 and leave it as:
 |
(5.15) |
Equation 5.15 is the cosine distance, and the intuition here is that the smaller the angle between the vectors, the closer they are to each other. So now you can ask me, why do I need all of this mathematics if I could simply calculate the cosine distance between the new user8 and the users in matrix A? Trust me, I have a severe allergy to work, and if this was not useful, I wouldn’t put it here. Take, for example, users, 3, 4, and 6. If we calculate the dot product between user8 and these other users in the space of the matrix A (users by song ratings), we will find that it is equal to 0. They are therefore not similar at all. And, users who don’t have ratings in common can represent a problem. To overcome such situations, we can transform user8 into the space of songs by context. Now, if we calculate the cosine distance between user8 contexts or genre values and the vectors in matrix U, we will get the user or users that are more similar to user8 in terms of context. It then follows that:

We are looking for the smallest angle value, as this dictates the proximity between vectors (and similarity between users). With this in mind, we can see that the users who are more similar to user8 are user7 and user2. We could therefore recommend a highly-rated song from these users to user8 if user8 have not yet rated it. One more useful thing that comes from the single value decomposition equation is that it can represent a matrix as a sum of outer products:

In this equation t is the number of single values selected for the approximation. Graphically, this equation has the following shape:

This means we can create approximate versions of the matrix A by selecting different numbers of single values, just like the truncated version of the SVDs. Let’s see what happens if we choose to approximate A with the first single value. For  , we have the vector:
, we have the vector:

The vector  is :
is :

Finally, for σ1, we have the scalar 15.72. An approximation of A with only a single value will be named A1∗; it can be represented by:

It follows that:

This is not a very good approximation as A is:

Let’s see what happens if we consider two singular values instead of one:

In this particular case, A2∗ seems to be a better approximation for A, which makes sense:

To verify if this is the case, we will make use of a norm, a measure of distance, called the “Frobenius norm”, as in the following formula:

If we calculate this norm for the differences between the matrix approximations and matrix A, it will provide a good idea of which is closer to A:

Why is this useful? Well, one purpose can be to store a vast matrix. For example, suppose you have a matrix of 1 million rows by 1 million columns and you choose to approximate it using the most significant singular value. In that case, it is only necessary to store two vectors of size ten and one scalar (the single value).
Before wrapping up, I would next like to introduce one more technique we mentioned at the start of this book that is widely used in machine learning.