What About a Matrix?
A matrix is a rectangular arrangement of numbers, symbols, or functions organized in rows and columns. In various contexts, a matrix may denote a mathematical object or an attribute of such an object. A key feature of these elements is their order or size, defined by the number of rows and columns. Matrices are commonly denoted by capital letters, and can be represented using the following notation:

In this representation, m is the number of rows and n is the number of columns. An example of a 3 × 3 matrix is:

If we wish to generalise a representation for all matrices, we can rewrite the one above in a form that will accommodate any case:

The a′s are referred to as an entry, with each of these being defined by their index. For instance, a11 is the element in the first row and the first column of the matrix. In machine learning, the use of matrices mainly accommodates three different cases. Let me explain.
4.1 When a Table Isn’t Furniture
There is one element without which we would be unable to do any work with machine learning algorithms; features. Features are what characterise your data. They are a set of metrics per element of granularity, from which your algorithm will try to learn signals. This same set can be represented as a vector, and, if you combine all the vectors into a single structure, you end up with a matrix. For example, say that we wish to predict whether a student will make it onto the basketball team based on their weight, height, and an average of their grades (assuming that their grades are a real number). Here the granularity, a word that reflects the level of detail present in the data, is the students, and the metrics are height, weight, and the average grade. Students can be represented by vectors:

Combining these vectors will produce a feature space matrix that can be placed alongside a target variable. An example of such a variable is a Boolean indicator; that’s just a fancy name for a variable that can only take two values, for example, yes or no. This variable will then exhibit whether or not a student made it onto the basketball team. This enriched data set can then be used to perform predictions:

4.2 Yoga for Vectors – Linear Transformations
The second representation of a matrix is a linear transformation. Bear with me; this is a concept that has the potential to change your learning experience of linear algebra. As this notion is related to movement in space, we can showcase it using visualisations. This will help to solidify a deep understanding of an idea that, although simple, is essential when it comes to understanding everything else in this book. It is an excellent tool to have in your arsenal, and it includes most of the techniques already studied.
Breaking down the term will give a pretty good indication of what we are dealing with. In fact, this is good practice in mathematics. After all, the names have to make some kind of sense. Actually, for a long time these names did not make sense to me because I always associated them with a formula, and never stopped to think about what the names truly meant. This cost me time, but for some reason, one random day, it clicked. I remember with which one it was, the standard deviation. I was walking along, and all of a sudden, almost like an epiphany, everything was clear in my mind. Standard deviation is how much data deviates from the standard. But what is the standard? Probably the mean. Following the happiness of this moment, one of the best sequences of letters (that works like a charm in the right situation) came to me out loud; Motherfucker!
Now, we have covered the meaning of the word linear: no curves please, so all lines will remain lines. Transformation is another word for mapping or function. Also, is it important to mention that, despite the tasks in hand, the origin of the vectors must remain intact in transformations. So we will be transforming vectors into vectors or scalars via matrices. Analytically, a linear transformation L between two spaces Z and R can be represented as:

The vector is going from Z to R via L. More rigorously, a linear transformation L is defined as:

Since we are not gonna be considering any complex numbers in this book, we can even be a bit more particular and define the linear transformations as:

This means we will move a vector from a space with n dimensions into a space with m dimensions. For the purpose of demonstration, let’s consider n = m = 2. I can give you an ego booster here; when n = m, the linear transformation is called an endomorphism. Don’t say I am not your friend, dropping all these fancy names.
We are defining a way to move a vector in space via patterns that allow it to keep its origin, but also to rotate and/or stretch. The transformation defined by L will map every vector in the same way. In the following example, L is a 180 degree rotation of any vector from the vector space ℝ2:

The plot bellow, is to showcase the fact that a linear transformation will do the same thing to every vector that we decide to map:

This transformation is defined by:


The letters, l1,l2 represent generic coordinates of a given vector, for example, given any vector  ∈ ℝ2, with coordinates (v1,v2) the linear transformation L will transform the coordinates of this vector into their negations, (−v1,−v2). Negation is not a depreciative term. It means the negative version of a positive number, or vice versa, and numbers do not have feelings, well, so far. Analytically, we have defined linear transformations, but we have yet to understand why we need matrices for these functions. To do so, let’s start by considering one basis of ℝ2, the one defined by
∈ ℝ2, with coordinates (v1,v2) the linear transformation L will transform the coordinates of this vector into their negations, (−v1,−v2). Negation is not a depreciative term. It means the negative version of a positive number, or vice versa, and numbers do not have feelings, well, so far. Analytically, we have defined linear transformations, but we have yet to understand why we need matrices for these functions. To do so, let’s start by considering one basis of ℝ2, the one defined by  and
and  where:
where:

So any vector that belongs to ℝ2 can be represented as:

Which is the same as having:
 |
(4.1) |
Where α,β ∈ ℝ. If you don’t believe me, I will dare you to find a vector that belongs to ℝ2 that can’t be obtained by equation 4.1. Let’s make this interesting, I will buy a car for the person that finds out about such a vector. Subscribe to the mailing list to participate in this context. Press Here! (Note: This is a marketing trick, don’t forget to erase this note before printing the book). Now, let’s grab a vector  ∈ ℝ2 and write it down as a linear combination of
∈ ℝ2 and write it down as a linear combination of  and
and  . If we select the values (2, 3)T as the coordinates of
. If we select the values (2, 3)T as the coordinates of  , it follows that:
, it follows that:
 |
(4.2) |
We defined L on the fact it will rotate any vector in ℝ2 by 180 degrees. If we apply this transformation to the basis  ,
,  and call the resultant vectors as
and call the resultant vectors as  ,
,  we have:
we have:

Alright, let’s grab equation 4.2 and replace  and
and  by
by  and
and  respectively:
respectively:

Here,  represents a new version of
represents a new version of  which is defined as a linear combination of the transformed base. It follows that:
which is defined as a linear combination of the transformed base. It follows that:

Well,  is the same as
is the same as  , meaning that
, meaning that  is the negated form of
is the negated form of  , exactly like we defined L. As a result, it is possible to represent a linear transformation by adding two scaled vectors:
, exactly like we defined L. As a result, it is possible to represent a linear transformation by adding two scaled vectors:

 and its basis.
and its basis.Generically, if  = (v1,v2) is any vector of ℝ2, a linear transformation can have the form:
= (v1,v2) is any vector of ℝ2, a linear transformation can have the form:

To transform a given vector from ℝ2, we can start by mapping the standard basis. Then, suppose we add the result of multiplying each of the elements of the original vector by the vectors of this transformed version of the basis, respectively. In that case, we will obtain the desired transformed vector. Let’s consider another example to solidify this important concept. Say that we now have G, a linear transformation where  and
and  are transformed into (2, 1)T and (1, 2)T. A vector that results from applying G can be described as
are transformed into (2, 1)T and (1, 2)T. A vector that results from applying G can be described as  :
:
 |
(4.3) |
We are missing the vector from which we desire to obtain a transformed version, the vector  . Let’s say that g1 and g2, the elements of
. Let’s say that g1 and g2, the elements of  , are equal to 1. Consequently, we have:
, are equal to 1. Consequently, we have:

So, it follows that:

If you are curious, this is the analytic representation of G:


And, visually, this is how we can represent this transformation:

 .
.Before moving onto a matrix representation of linear transformations, there is something else to cover. We’ve spoken about changing basis, linear transformations, and changing basis with linear transformations. A change of basis is not a linear transformation. You can do a change of basis via an isomorphism, which is a linear transformation between the same spaces. Remember that changing the basis just changes the perspective of the same vector, whereas a linear transformation, as the name suggests, can change the vector; it is a transformation. For example, consider an arbitrary mapping from ℝ2 to ℝ3:
 |
(4.4) |

The equation 4.4 can’t represent a change of basis, but a linear transformation sure can. It is true that we did not define the conditions that a mapping has to obey in order for it to be considered linear. But it is Sunday, and I was hoping that you would let this one slide… no? Forward we move then. A linear transformation L : ℝn → ℝm must satisfy two conditions:
- L(
 +
+  ) = L(
) = L( ) + L(
) + L( )
) - L(c ⋅
 ) = c ⋅ L(
) = c ⋅ L( )
)
For all vectors  ,
, ∈ ℝn and all scalars c ∈ ℝ. Alright, let’s verify if H satisfies the two conditions above. On H we go from ℝ2 to ℝ3 so we can define
∈ ℝn and all scalars c ∈ ℝ. Alright, let’s verify if H satisfies the two conditions above. On H we go from ℝ2 to ℝ3 so we can define  and
and  as (v1,v2) and (u1,u2). The plan of attack will be to get the left side of the item’s one equation and develop to see if we arrive at the equation on the right of the same item’s number. We need (
as (v1,v2) and (u1,u2). The plan of attack will be to get the left side of the item’s one equation and develop to see if we arrive at the equation on the right of the same item’s number. We need ( +
+  ) which is the same as (v1 + u1,v2 + u2). Now this specimen will go for a ride via H:
) which is the same as (v1 + u1,v2 + u2). Now this specimen will go for a ride via H:


I know that stuff is so ugly that if it could look at a mirror its reflection would walk away, but it is what we have to work with. Now for the second part we need H( ) and H(
) and H( ) to calculate H(
) to calculate H( ) + H(
) + H( ). So:
). So:

On the other hand:

Adding them up results in:

Which is exactly what we are looking for. Now for item number two, let’s start with H(c ):
):




And that proves point number two! This means that we are assured that H is a linear transformation, and there is the opportunity to learn two more fancy names: for item one we have additivity whereas item two is homogeneity.
I want for us to go back to equation 4.3, where we defined the vector  via a linear combination.
via a linear combination.

There is another way of representing such a transformation; we could do so via a matrix.

To go from one notation to the other, from analytical to a matrix, is very simple. Each row of the matrix will have the coefficients of the variables of each element of the linear equation above. So, the first row of matrix G is 2, 1 because the coefficients of the first element (2.g1 + g2) are two and one. The second line of the matrix follows the same logic. The conclusion is that a linear transformation can also be characterised by a matrix.
We now know about vectors and matrices, but we don’t have a way of operating between these two concepts, and in fact, this is what we are missing. To transform any vector with that matrix G, we need to multiply a vector by a matrix.
4.2.1 Could It Be Love? Matrix and Vector Multiplication
Matrix and vector multiplication can be summarised by a set of rules. A method that is appealing to some people for reasons that I will leave to your imagination. On the other hand, I have a very hard time with such things, so instead of just providing a formula to compute these multiplications, we will deduce it. We are not cooking; we are learning mathematics. You shouldn’t be happy because you have a set of instructions to follow. Save that for your bad-tasting vegan dessert. I am just joking. I know you are all foodies that know more than people that spent half of their lives cooking.
Let’s consider any vector, which we’ll call  (we need a x in a mathematics book, so it was about time!), and a matrix A. There is one consideration to bear in mind when defining matrix-vector products, their dimensions. We can only compute this multiplication when the number of columns in A is equal to the number of rows in
(we need a x in a mathematics book, so it was about time!), and a matrix A. There is one consideration to bear in mind when defining matrix-vector products, their dimensions. We can only compute this multiplication when the number of columns in A is equal to the number of rows in  or the number of columns in
or the number of columns in  is equal to the number of rows in A. So for any matrix Am×n we can only compute multiplication with vectors of the order
is equal to the number of rows in A. So for any matrix Am×n we can only compute multiplication with vectors of the order  n×1. We can then represent, A ⋅
n×1. We can then represent, A ⋅ as:
as:
 |
(4.5) |
Time for a confession. The term role model would not have applied to me as a student. Under my name on the attendance report, things were not pretty. This lack of showing up is not something that I am proud of these days. I could have learned way more in university, but everything has its positives and its negatives. I missed a lot of classes, but I never flunked. This is because I developed a strategy. Where and when I took my degree, it was not mandatory to go to class; you could just show up on the exam date, and if you scored more than 50%, the job was done. You can’t fully understand a whole semester of classes a week before the exam. That was an easily reachable conclusion. So now I was seriously debating, how could I pass this exam by not attending classes all the time? In the discipline of mathematics, you tend to encounter a dependence on prior knowledge to understand what will come next. You could see it as a problem, but I chose to see it as an advantage. The things you learned in the first weeks of classes will likely be a basis for more complex deductions, concepts, and theorems. So, if you have a solid foundation but need to get to more complex themes, then with some creativity, inspiration, and maybe a little bit of lady luck on your side, you could… wing it. So my strategy, as time was of the essence when studying for an exam, was to just focus on the basics: everything I needed that allowed me to deduce a concept if required.
I am not advocating for people to do this. The fact that I did not attend classes as often as I should have is the sole reason behind my average grades during my degree. Gladly, this changed during my Master’s. I worked harder. The positive from this is that I always ensure that I understand the basics well, which has also helped me immensely in my career as a mathematician that has the job title of data scientist. Now in this book, is there anything that we can use to do something to a big ass matrix and a vector? Well, what about the dot product? Let’s try it. If we compute the dot product row by row on equation 4.5, we will end up with:

Let’s go back to where we finished the exposition of linear transformations with matrix G:

And we need a 2 × 1 vector, so let’s put  to work again:
to work again:

If we were to multiply G and  :
:

Given that we used G and  on the example above is not a surprise that if we wish to transform a vector by making use of a linear transformation, we just need to multiply this vector by the matrix. Now, let’s define the matrix for the linear transformation H:
on the example above is not a surprise that if we wish to transform a vector by making use of a linear transformation, we just need to multiply this vector by the matrix. Now, let’s define the matrix for the linear transformation H:

Alright, let’s do some verifications with  :
:

The linear transformation H is defined such that the new vector is given by (7h1 + 0h2, 2h2 + h1,h1 + h2) so if we replace h1 with 1 and h2 with 1 we end up with the same result (7, 3, 2). Cool stuff! This is another use case for a matrix, the representation of a linear transformation. And on the way to understanding it, we introduced matrix-vector multiplications. If a matrix is a set of vectors and we can multiply a vector by a matrix, what is stopping us from multiplying two matrices? Surely not me. Given two generic matrices An×m and Bm×p, actually throw one more into the mix, it is happy hour, let’s say that Cn×p is the result of A ⋅ B, so if:

And:

Then each column of C is the matrix-vector product of A with the respective column in B. In other words, the component in the ith row and jth column of C is the dot product between the ith row of A and the jth column of B such that:

Visually this is what we will have:

Let’s check a numerical example. Say that A4×2 is such that:

And let’s define B2×3:

Then:


It is simply not enough. We are manipulating vectors with dot products and dealing with linear transformations. Something is happening in the vector space, and it shouldn’t go to the Vatican to be kept a secret. Consider:


The matrix that represents the linear transformation Z is:

Transforming the vector  with the linear transformation Z results in:
with the linear transformation Z results in:


 by Z.
by Z.Now I will define another linear transformation. We will get somewhere, don’t worry, I haven’t lost my mind. I don’t know how to convince you of this, as I think that everybody that loses their mind will state that same sentence, nevertheless, give me a chance. Let’s say that W is defined such that:


It would be interesting to see what happens to vector  if we transform it with W. In other words, we are exploring the idea of composing transformations. We are looking at transforming one vector via a matrix and mapping the resultant element with another matrix. So, we will transform the vector that results from changing
if we transform it with W. In other words, we are exploring the idea of composing transformations. We are looking at transforming one vector via a matrix and mapping the resultant element with another matrix. So, we will transform the vector that results from changing  with Z via the matrix W:
with Z via the matrix W:


 by W.
by W.The vector  is no stranger to us. It is the same as the vector
is no stranger to us. It is the same as the vector  we obtained when we introduced the subject of linear transformations and used the mapping G as an example. This did not happen by accident, I fabricated this example to showcase a composition, so let’s multiply the two matrices W and Z:
we obtained when we introduced the subject of linear transformations and used the mapping G as an example. This did not happen by accident, I fabricated this example to showcase a composition, so let’s multiply the two matrices W and Z:

This is the matrix that defines the linear transformation G, which means that when we are multiplying matrices, we are composing a transformation. We are transforming a vector in one step instead of two. While two applies to this particular case, you can have as many steps as there are matrices that you wish to multiply. This is a good way of looking at matrix multiplication rather than just thinking of a formula. Now you can see that you are just taking a vector for a ride. Either you do it in steps if you wish to multiply the vector by one of the matrices in the multiplication, and then multiply the result of this by the next matrix and so on. Or you can do it in one go and multiply the vector by the resultant matrix of the multiplication.
Never forget that order matters, oops I forgot to mention it, so let’s introduce some matrix multiplication concepts. Contrary to multiplication with real numbers, multiplying two matrices is not commutative, meaning that if A and B are two matrices:

The dimensions of the matrices are also critical, you can’t just multiply any two matrices, just like the case of matrix-vector multiplication. The number of columns in the first matrix must be equal to the number of rows in the second matrix. The resultant matrix will then have the number of rows of the first matrix and the number of columns of the second matrix:

There are several ways to multiply matrices, but as we are dealing with linear mappings (we will also introduce linear systems later), we need to pay attention to the dimensions. Finally, the product of matrices is both distributive and associative when dealing with matrix addition:
- A(B + C) = AB + AC
- (B + C)D = BD + CD
I feel that we are on a roll here with these concepts of multiplication, so I will take the opportunity to present a new way of representing the multiplication of two matrices, if I may. Let’s consider two generic matrices, A and B:

If we multiply A and B it follows that:

We can split this into the sum of two matrices:
 |
(4.6) |
Right, let’s take a look at matrix  , there are a´s, e’s, c’s, and f’s. Don’t worry; we will not be singing songs about the alphabet. Those letters are in the first column of A and the first row of B, and it seems that I just have to multiply each entry of one with each entry of the other:
, there are a´s, e’s, c’s, and f’s. Don’t worry; we will not be singing songs about the alphabet. Those letters are in the first column of A and the first row of B, and it seems that I just have to multiply each entry of one with each entry of the other:

 This technique is called the outer product and it is represented by the symbol ⊗. For some reason, for a while, I would have an anxiety attack every time I saw that symbol on a blackboard at university, and now I understand why I feared the notation. There is no reason to fear an equation. They are the syntax of mathematics, the same way that music has symbols and shapes which form notes and tempos. So in terms of notation, if we have vector
This technique is called the outer product and it is represented by the symbol ⊗. For some reason, for a while, I would have an anxiety attack every time I saw that symbol on a blackboard at university, and now I understand why I feared the notation. There is no reason to fear an equation. They are the syntax of mathematics, the same way that music has symbols and shapes which form notes and tempos. So in terms of notation, if we have vector  with dimensions n × 1 and vector
with dimensions n × 1 and vector  with dimensions m × 1, and their outer product is computed as:
with dimensions m × 1, and their outer product is computed as:

This is an operation between two vectors. But, the reason I chose to introduce it while we are dealing with matrices is: well, the first reason is that the result is a matrix. As for the second reason, we can put this operation into context. Going back to equation 4.6, we divided the multiplication of A and B into a sum of two matrices, and followed this with a new way of computing a matrix via the outer product of two vectors. This technique allows us to represent matrix multiplication as a sum of outer products. The outer product of the vectors (b,d) and (g,h) provides the right side of the summation on equation 4.6, so we can generalise the formula for multiplication of matrices as a sum of dots products:

Where ColumniA is the ith column of A and RowiB is ith row of B. There are several applications for representing matrix multiplication as the sum of outer products. For example, if you have a sparse matrix (a matrix in which most entries are zero) you can speed up the computation taken to multiply two matrices by this representation. Another example is the derivation of an approximation of matrices via matrix decomposition, such as a single value decomposition, which we will cover in this book, so bear with me.
By looking at linear transformations, we had the need to understand several other concepts that while not complicated, were of extreme importance. We went on a ride there with the linear transformations (just like the vectors), and I can tell you that by now, you are most likely capable of understanding any concept in linear algebra. Just think about what we’ve covered so far: vectors, dot products, matrices, linear transformations, outer products, the multiplication of vectors by matrices, as well as matrices by matrices. One cool thing you can do with linear transformations is to transform shapes. For example, you can shrink or extend a square into a rectangle, and with this comes a useful concept in linear algebra, the determinant.
4.2.2 When It’s Not Rude to Ask About Size – The Determinant
Linear transformations are a fundamental concept in linear algebra; they allow the rotation and scaling of vectors in the same space or even into new ones. We can also use this mathematical concept to transform geometric figures, like a square or a parallelogram. If we take a two-dimensional space, such formations can be represented by a pair of vectors and their corresponding projections. Let’s use the standard basis  = (1, 0)T and
= (1, 0)T and  = (0, 1)T and form a square:
= (0, 1)T and form a square:

Following on from this, we can define a linear transformation represented by the matrix:

Applying the mapping L to  and
and  will result into two new vectors,
will result into two new vectors,  and
and  , with values (2, 0)T and (0, 2)T respectively. If we plot them alongside their projections, this is what it will look like:
, with values (2, 0)T and (0, 2)T respectively. If we plot them alongside their projections, this is what it will look like:

Visually, the area of the square formed by the basis vectors quadruples in size when transformed by L. So, every shape that L modifies will be scaled by a factor of four. Now, consider the following linear transformation H defined by:

If we apply H to the vectors  and
and  we will end up with
we will end up with  and
and  with values (
with values ( , 0)T and (0,
, 0)T and (0, )T:
)T:

In this instance, the area of the parallelogram shrunk by a factor of four. The scalar that represents the change in area size due to the transformation is called the determinant. In the first example, we have a determinant equal to four and the second example has a determinant of one quarter. The determinant is then a function that receives a square matrix and outputs a scalar that does not need to be strictly positive. It can take negative values or even zero. For example, consider the transformation Z such that:

To spice things up a little, and I mean it when I say a little bit. Once upon a time in Mexico, I decided to play macho and asked for a very spicy dish. So let’s say that I and the Mexican sewer system had some rough next few days. Let’s consider two new vectors:


The image above represents a determinant with a negative value. It might seem strange as the determinant represents a scaling factor. But, the negative sign indicates that the orientation of the vectors has changed. The vector  was to the right of
was to the right of  and after the transformation,
and after the transformation,  is to the left of
is to the left of  . Due to this property, the determinant can also be called the signed area. What we are missing is a formula to compute this bad boy, so let’s consider a generic matrix M:
. Due to this property, the determinant can also be called the signed area. What we are missing is a formula to compute this bad boy, so let’s consider a generic matrix M:

The notation for the determinant is det(M) or ∣M∣, and the formula for its computation is:
 |
(4.7) |
Why? It is a fair question. Let’s bring up a plot to understand what is going on. We have been speaking about areas, so a visual should indicate why the formula is as shown above:

The quest now is for the area of the blue parallelogram. At first glance, it does not seem like a straightforward thing to compute, but we can find a workaround. We can start by calculating the area of the big rectangle, formed by (a + b) and (c + d), this can be found by (a + b)(c + d). We don’t know the area of the blue parallelogram, but we know that of the shapes around it: four triangles and two squares. So, if we subtract the sum of these from the big rectangle, we end up with the area value of the blue parallelogram. The two brown triangles each have an area of  , which when summed is bd, so we need to remove bd from the big parallelogram. The two pink squares are each of size bc, which when summed equates to a value of 2bc. And finally, the green triangles are each of size
, which when summed is bd, so we need to remove bd from the big parallelogram. The two pink squares are each of size bc, which when summed equates to a value of 2bc. And finally, the green triangles are each of size  , adding them will result in a magnitude of ac. If we sum each of these areas, we arrive at an expression for the value that we need to subtract from the big rectangle area:
, adding them will result in a magnitude of ac. If we sum each of these areas, we arrive at an expression for the value that we need to subtract from the big rectangle area:

Alright, let’s check what happens if we apply equation 4.7 to the linear transformation Z:
 |
This means that the resultant area of a shape transformed by Z will remain the same, but the orientation of the vectors will change, just as we saw in the plot above. If we have a higher dimensionality than two, we will be scaling volumes instead of scaling areas. Consider a generic 3 × 3 matrix, N such that:

Graphically, the determinant will reflect the change in volume of a transformed parallelepiped:

Before jumping into the derivation of the formula to compute a 3 × 3 determinant, I would like to introduce three properties of this algebraic concept:
- If we have pair of vectors that are equal, its follows that det(
 ,
, ,
, ) = 0. Graphically we can prove this. For example, if we collapse
) = 0. Graphically we can prove this. For example, if we collapse  into
into  , we understand that the parallelepiped will also collapse and become flat.
, we understand that the parallelepiped will also collapse and become flat. - If we scale the length of any side of the parallelepiped, we will also scale the determinant, det(a ⋅
 ,
, ,
, ) = a ⋅ det(
) = a ⋅ det( ,
, ,
, ), where a ∈ ℝ.
), where a ∈ ℝ. - The determinant is a linear operation, det(
 +
+ ,
, ,
, ) = det(
) = det( ,
, ,
, ) + det(
) + det( ,
, ,
, ).
).
These properties are valid for any dimensionality of a geometric shape that we wish to calculate a determinant for, but for now, I would like to do an experiment and use one of these properties to produce the same formula that we have for a matrix of size 2 × 2. For this, let’s formulate the calculation of a determinant such that:

We can represent these vectors as a linear combination of the standard basis vectors ,
,  :
:
 |
(4.8) |
I feel that there are a ton of letters and no numbers, and I don’t want to scare you off, so let’s do a verification:

There! Some numbers to ease us into what’s about to happen. We can make equation 4.8 look more friendly by leveraging property numero tres:

This can also be made a bit simpler:


Now, by property two we can take those scalars out:
 |
(4.9) |

OK, we can do something with this. If a matrix has identical vectors for columns, it follows that the determinant value is 0. So, ab⋅det( ,
, ) = 0 and cd⋅det(
) = 0 and cd⋅det( ,
, ) = 0. The only two things that are missing are the values of det(
) = 0. The only two things that are missing are the values of det( ,
, ) and det(
) and det( ,
, ). This will be the same matrix, but with switched rows. Let’s see what happens to the determinant when we do such a thing:
). This will be the same matrix, but with switched rows. Let’s see what happens to the determinant when we do such a thing:

And:

So, equation 4.9 is equal to:

Which is what we found when we made the geometric deduction. I included this because we can do the same kind of exercise for a matrix with dimension 3 × 3, for example, the matrix N. This time I will save you from all the intermediate steps (as they are very similar to those for two dimensions) and I’ll provide you with the final result:
 |
(4.10) |
We can reorganise the equation 4.10 to:
 |
(4.11) |
And we can also produce a less condensed version of equation 4.11:
 |
(4.12) |
Which has the following graphical representation:

For any matrix with a dimensionality lower than four, we are sorted. The only matrix sizes we are missing are four, five, six, and seven … damn, there is still a lot to cover! It is formula time. For that, let’s introduce a new bit of notation. I chose not to do this earlier as I felt it would have become a bit intense too soon, but for what we have to understand now, it will be of extreme utility. Let’s redefine the entries of N as:

So if we write equation 4.10 following this new notation, it comes that:
 |
(4.13) |

As before, we have to work with what we have. Equation 4.13 is made up of sums and subtractions of the different iterations of multiplications of the elements of N (that’s a mouthful, I know!). The suggestion is that we could probably use the Greek letter Σ (used for summations) to represent what we are trying to deduce, that being a general formula for the determinant. It sounds like a good idea, but if we add elements, how will we take care of those negative signs in equation 4.13? We have six terms when calculating the determinant of a three-dimensional matrix, and two when working with a matrix in two dimensions. It follows that the number of terms in the determinant equation is equal to the factorial of the matrix dimensions.
Skip this paragraph if you already know this bit, but a factorial is represented by !, and it refers to the combinations one can construct by using elements described by n. For example, in the case that n = 3, we have six ways of combining three components, as reflected in equation 4.13. The formula for the factorial is then the multiplication of each positive integer less than or equal to n, so 3! = 3 ⋅ 2 ⋅ 1 = 6.
Alright, so I now know the number of elements for the determinant of a given matrix size, but how will this help with the plus and minus signs? This is where we have to introduce the notion of a permutation, which is a way to order a set of numbers, and in the case of three dimensions, we have six different permutations. For example consider the numbers (1, 2, 3): we can have six forms of representing this set (1, 2, 3), (1, 3, 2), (2, 1, 3), (2, 3, 1), (3, 1, 2) and (3, 2, 1). We can define a permutation function π that represents these iterations, for example:
 |
(4.14) |
Equation 4.14 represents the changes to the original set in order to produce the permutated set. One goes to three, two stays the same, and three goes to one. So π(1) = 3. These functions come with a definition that we can leverage. It is called the parity of a permutation, and it tells us the sign of such a mathematical concept. Specifically, it states that the number of inversions defines the sign of a permutation. So, it will be +1 if we have an even number of inversions and −1 if the value is odd.
Curiosity has struck me more than once on why non-even numbers are called odd; if you want my honest answer after spending many hours researching this, my conclusion is that I wish I could have that time back! On my journey, I went all the way from shapes defined by the ancient Greeks, to bathroom philosophy on world views and representations, all to no avail.
Anyhow to calculate the number of inversions, we need to check it for pairs. It then follows that we will have an inversion for a pair (x,y), if we have x < y, and π(x) > π(y). Let’s go back to the example in equation 4.14, but this time for the pairs when x < y: (1, 2), (1, 3) and (2, 3). Now π(1) = 3, π(2) = 2 and π(3) = 1 so:
- 1 < 2 and π(1) > π(2) it is an inversion.
- 1 < 3 and π(1) > π(3) it is an inversion.
- 2 < 3 and π(2) > π(3) it is an inversion.
We arrive at a result where the sign of (3, 2, 1) is negative. If we look into the monomials of equation 4.13 we could define permutations and, consequently, functions from the indices of the elements that are part of them. If you are wondering, 4.13 is a polynomial made up of monomials. Monomial is just a lame name for product of variables and/or constants, where each variable has a non-negative integer exponent. A polynomial is a set of monomials, which make it super lame? I leave this one for you to decide. For example n11.n22.n33 is one of these. Since we are speaking about this particular guy, let’s try to understand what exactly I’m talking about. We have three pairs (1, 1), (2, 2), and (3, 3), which means that the function π that represents this is:

This case is just like an election; nothing changes! So, the number of inversions is equal to zero, and therefore the sign is positive. This means that if we do this exercise for the five remaining monomials and if the parity sign is the same as that in the equation, we may have found what we were looking for: a way to control the minus or plus sign in a formula to calculate a determinant via a summation.
Let’s check:
 |
(4.15) |
A quick way to detect inversions is to check which pairs appear in the wrong order, for example in the function π : 312, the pairs (1, 3) and (2, 3) are inverted; therefore, the sign must be positive. It is true that with just this, we can create a formula for the calculation of the determinant. Now, it will be ugly as hell, but it will work:
 |
(4.16) |
A is a square matrix and n is the total number of permutations. We can test this formula with a 2 × 2 matrix M. So, in the case of a matrix of size two, we have the same number of permutations as for the size, 2! = 2 ⋅ 1 = 2. They will be (1, 2) and (2, 1), so we will sum two terms. The first is related to the permutation (1, 2), and we need to define π for this case: π : {1, 2}→{1, 2}. It follows that π(1) = 1 and π(2) = 2, so the first term of the equation is sign(π) ⋅ m11 ⋅ m22. The sign(π) is positive because nothing changes: there is no inversion. If we apply the same logic to the second term, we will have sign(π) ⋅ m12 ⋅ m21 as π(1) = 2 and π(1) = 2. In this case, we have one inversion, so the sign of π is negative. It then follows that:

Which is exactly the same as equation 4.7. It is true that equation 4.16 is enough to calculate any determinant, but we can do better than that. I mean, come on, that will be a nightmare for dimensions higher than three! Something curious happens in equation 4.12; we have three pivots and three lower dimensioned determinants. Let’s start with the determinants to write equation 4.12 as:
 |
(4.17) |
There are new individuals in equation 4.17, the determinants represented by the letter M. Allow me to introduce you to the minors. A minor is the determinant of a square matrix that results from removing some rows and columns from the original matrix. The clue on which row and column to remove is in its index, so, for example, M11 suggests that we should remove the first row and the first column from the original matrix:
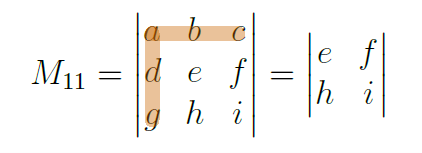
The only elements we haven’t spoken about from equation 4.12 are the pivots, another name I know, but these are just the fellows a, b and c. They happen to all be on the same row. We can generate a new formula for the determinant with all of this information. I have a suggestion, what if we fix a row or a column? Let’s start with a column, and we can define the determinant such that:
 |
(4.18) |
If we set i = 1, we obtain equation 4.17. The question now, is whether equation 4.18 works for n dimensions? And the answer is yes, it does. But, there’s more we can say, as this theorem has a special name, the Laplace expansion:

The Laplace expansion works for any row with a fixed column, or for any column if we fix the row. The determinant formula has been broken down, but there is another linear algebra concept we can learn from this, the cofactors. Don’t worry. You have enough knowledge to compute these as they are a part of the formula for the determinant. So, if you multiply (−1)i+j by the minor Mij, you will then be computing the cofactor Cij. The result of this will be a real number because we are multiplying the resultant of a determinant by 1 or -1. In the example above, where we derived the minor M11, the cofactor C11 is equal to:

Meaning that each entry of a square matrix will have a cofactor, and therefore we can define a matrix of cofactors as:

Ending this with an example will be the best way I feel. So, say that we have G, a 3 × 3 matrix defined as:

Let’s use the Laplace expansion to compute the determinant. I will select the first row, so j = 1. For my pivots I will have positions g11, g21 and g31 and the signals are +,-,+ respectively. For minors with j = 1 we have M11, M21 and M31. Okay, we have everything we need for this calculation, so let’s get it done:

Which is the same as:

The result is

While I don’t imagine that anyone will be doing a lot of manual computation of the determinant, understanding it is crucial. And if you think that the only use for it is to understand the scale and direction of transformation, you have got another thing coming, as determinants can also be used to invert matrices.
4.2.3 Let’s Go The Other Way Around – Inverse of a Matrix
Would you send a friend from your house to another location without telling this person how to get back? Then why the hell would you do this to a vector? We now know that matrices can represent linear transformations and we also know that this mathematical concept transforms vectors in space. If A is a linear transformation, then, its inverse is also a linear transformation. The difference is that the inverse of A returns the vector back to its initial state. Just as any real number has an inverse, a matrix will also have an inverse, well… OK, I admit not all of them do. In reality, there is a condition that the determinant of such a matrix must meet. If the inverse matrix depends on the determinant, then this same matrix must consequently be a square matrix. There is a particular case for a determinant value that is worth taking a closer look at, namely when the value is 0. If the determinant is a scaling factor, what will it mean if we change the shape by a value of 0? It means that we have lost at least one of the dimensions. In the case of a parallelogram, the result will be a line or a point. An example would be:

Consider two vectors  = (3, 1)T and
= (3, 1)T and  = (1, 2)T such that:
= (1, 2)T such that:

Now let’s calculate the coordinates of the new vectors  and
and  which are the vectors that result from transforming
which are the vectors that result from transforming  and
and  by G. This means that
by G. This means that  = (4, 4)T and
= (4, 4)T and  = (3, 3)T:
= (3, 3)T:

 and
and  via G.
via G.As expected, the two transformed vectors landed on the same line, and therefore the area of the blue transformed parallelogram is 0.
There is no way to return to the original parallelogram once we arrive on a point or a line, at least with linear transformations. Hence, the second condition for a matrix to have an inverse is that the determinant must not be 0. The last condition is similar to what with real numbers. Consider the inverse of 5. It is defined by x ∈ ℝ such that 5.x = 1, meaning that x =  . The concept is the same in the case of matrices, but multiplying two matrices won’t result in a scalar. It will result in a special matrix called the identity, represented by In. The identity is a matrix in which all elements on the diagonal have a value of 1 and all of the non diagonal elements are 0. The matrix diagonal is formed by all the elements aij = 1 where i = j:
. The concept is the same in the case of matrices, but multiplying two matrices won’t result in a scalar. It will result in a special matrix called the identity, represented by In. The identity is a matrix in which all elements on the diagonal have a value of 1 and all of the non diagonal elements are 0. The matrix diagonal is formed by all the elements aij = 1 where i = j:
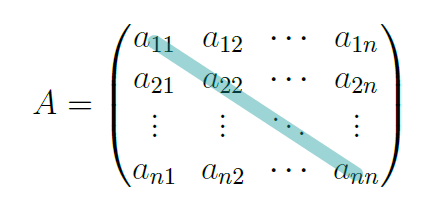
The identity matrix can then be defined as:

To arrive at a glorious finish with the hope of prosperity, we still need two more things: a visual way to compute the inverse of a matrix, and a numerical example. Moving on to the visualisations:

 .
.In the plot,  is (0, 1)T and its transformation
is (0, 1)T and its transformation  takes values (−1, 0)T. So, the linear transformation responsible for this (responsibility is terrifying when it’s said out loud, every time somebody asks ‘who’s responsible’ for something, you know something is coming) can be defined as:
takes values (−1, 0)T. So, the linear transformation responsible for this (responsibility is terrifying when it’s said out loud, every time somebody asks ‘who’s responsible’ for something, you know something is coming) can be defined as:

What we wish to do now is derive M−1 such that M ⋅ M−1 = I, right? Yes, this is what we defined previously. As this is a simple example, we know that, in order to calculate M−1 we need to define a linear transformation that also does a 90 degree rotation, but in the other direction. So, let’s do it in two steps. Firstly, to rotate a vector 90 degrees clockwise, one needs to place the original y coordinate of the vector in the place of the x coordinate and then place the inverse of the initial x coordinate, −x, in the place of the original y coordinate, such that:


Let’s test this out. If we transform  with the linear transformation M−1, we should get the vector
with the linear transformation M−1, we should get the vector  such that:
such that:

Which is precisely the vector  . So, in theory, if we multiply M by M−1, we need to get I, the identity matrix. Otherwise, something is not right:
. So, in theory, if we multiply M by M−1, we need to get I, the identity matrix. Otherwise, something is not right:


So far, we have defined a few properties regarding the inverse of a matrix, and I feel that it is a good moment to put them in a little box to produce a summary of where we stand. So, if A is such that A−1 exists, this means that:
- A is a square matrix.
- A−1 is such that A ⋅ A−1 = I.
- The determinant of A is not 0. I will throw another name your way, generosity is the word of the day. When a matrix has this property, it is called non-singular.
The question now is how can we compute an inverse of a matrix? There is a relationship between the determinant of the multiplication of two matrices. We can show that this is equal to the multiplication of the matrix determinants:
 |
(4.19) |
If we replace B with the inverse of A:
 |
(4.20) |
From equation 4.19 we can write 4.20 as:

It follows then that:

Finally we have:

There is some new information in this formula, I am talking about adj(A). Thankfully, we have enough knowledge to derive this very easily. The adjugate is simply the transpose of the cofactors matrix, C, so we can express this as:

If you do not recognize the T exponent associated with a matrix, don’t worry, papy is here once more to hold your hand. This means that we will swap the rows with the columns, implying that a matrix with dimensions n × m will become a matrix with dimensions m × n, for example:

The transpose of this matrix will still be a matrix, and the notation for it is AT. The resultant matrix will be:

Given that we have computed the transpose of a matrix for a particular case, let’s derive the general formula, so we can apply it to any matrix or vector of any dimension. A transposed matrix of dimensions n × m is a new matrix of size m × n in which the element in the ith row and jth column becomes the element in the ith column and jth row:
![[ ] AT = [A ] ij ji](https://static.packt-cdn.com/products/9781836208952/graphics/beforeMachineLearningVol1LinearAlgebraV2552x.svg)
Don’t worry, I did not forget the numerical example! Let’s say that the matrix A is defined as:

Now we need to compute the determinant and the adjugate:


Finally it follows that that the inverse of A is:

The matrix A is known to us. We used it when speaking about a change of basis. The vector that we used at the time was  = (2, 3)T and the coordinates of
= (2, 3)T and the coordinates of  in the new basis were (5, 3)T. So, we must obtain (2, 3)T if we multiply (5, 3)T by A−1. We will now be sending this vector back:
in the new basis were (5, 3)T. So, we must obtain (2, 3)T if we multiply (5, 3)T by A−1. We will now be sending this vector back:

Bullseye! That is precisely the result we were looking for, so 50 points for us!
This all started with a linear transformation, but we ended up covering a lot of linear algebra concepts that are needed if we are to fully understand these functions. Mastering mappings that promote movement amongst vectors was crucial in my machine learning journey as a data scientist. The graphical component of such a concept allowed me to think about matrices differently, as a vehicle for movement in space. By doing this, ideas like multiplication of a vector by a matrix, matrix to matrix multiplication, determinants, and inverting matrices became explicit, as I had developed a visual concept of what was happening with these notions when they are applied. If you are wondering where to use all of this mathematics in machine learning, well, neural networks are an excellent example to study. And there is yet another case for matrix representation that is worth exploring: systems of linear equations.
4.3 Gatherings in Space – Systems of Linear Equations
First, let’s define a system; and to do that, we will use a vernacular that would impress any executive in an interview room. A system is a collection of components that accepts an input and produces an output. When these systems are linear, we have robust mathematical definitions and concepts that allow us to extract such outcomes, which we can also call solutions. Well, as this book is about linear algebra, this robustness will be provided through methods that we can derive with all of the knowledge we’ve acquired so far. For the components we have linear equations, and for the inputs and outputs we have vectors. A linear system will then be a set of linear equations that receives a vector and produces one, several, or no solutions. For illustration purposes let’s consider a two dimensional scenario as a generic system that we can represent with the following notation:
 |
(4.21) |
In the system 4.21, elements a,b,c,d,e,f are scalars that belong to ℝ and define the system by characterizing two equations which are lines. The solution is defined by x1 and x2, which can be unique, nonexistent, or non-unique:

The plot above provides a graphical interpretation of some possible type of solutions of a linear system. The blue and yellow lines have for features the scalars a,b,c,d,e,f. If the values are such that the lines are parallel (as shown in the left-hand graph), then the system has no solutions. Conversely, if the lines land on top of each other (as shown in the middle plot), then the system has an infinite number of solutions. Lastly, as seen in the right-hand graph, if the lines intersect each other, this reflects the case where a system has a unique solution. Where are the matrices and the vectors? I miss them too, just like a dolphin misses SeaWorld. But don’t worry, we can represent the system 4.21 with matrix-vector notation:

The letter A represents a matrix whose elements are the scalars a,b,c,d. The vector  is the solution we are looking for (if it exists). Finally,
is the solution we are looking for (if it exists). Finally,  is another vector. The best way to define this vector is to look at linear transformations. If A represents a linear transformation, then what we are saying here is that we want to find a vector
is another vector. The best way to define this vector is to look at linear transformations. If A represents a linear transformation, then what we are saying here is that we want to find a vector  , that when transformed by A, lands on
, that when transformed by A, lands on  . So,
. So,  is where the solution has to land after being transformed by A. Our system can be defined by:
is where the solution has to land after being transformed by A. Our system can be defined by:

If we perform that multiplication, we will end up with the same system of equations 4.21, and the symbol  means that we are looking for an interception. However, it is also true that these systems can have as many equations as we wish with as many variables as desired. Consequently, finding a solution for some of them can be portrayed as complicated. Spending a long time doing calculations, only to conclude that there is no solution, is not ideal. Gladly with a matrix representation of such systems, we can understand what is the deal with these so-called solutions, before, doing any calculations towards finding them. We know that for two vectors to intercept somewhere in space, they need to be linearly independent. Therefore, the determinant of a matrix that has these same vectors for columns cannot be zero. From this, it follows that for a system to have a unique solution, the determinant of the matrix that represents the system must be non-zero.
means that we are looking for an interception. However, it is also true that these systems can have as many equations as we wish with as many variables as desired. Consequently, finding a solution for some of them can be portrayed as complicated. Spending a long time doing calculations, only to conclude that there is no solution, is not ideal. Gladly with a matrix representation of such systems, we can understand what is the deal with these so-called solutions, before, doing any calculations towards finding them. We know that for two vectors to intercept somewhere in space, they need to be linearly independent. Therefore, the determinant of a matrix that has these same vectors for columns cannot be zero. From this, it follows that for a system to have a unique solution, the determinant of the matrix that represents the system must be non-zero.
Less talking, more examples, right? Consider a system defined as:
 |
(4.22) |
We now should verify if there is a solution for the system 4.22. For that, we need a matrix A:

The determinant of A is then calculated by:

The coast seems to be clear. We have a non-zero determinant, meaning that this system will have a unique solution, and we can proceed to learn how to calculate it. But, before jumping into the deduction of a methodology to find solutions for a system, let’s quickly go over an example where the determinant is zero. Say that B is:

The determinant of B is equal to zero, det(B) = 3 ⋅ 2 − 6 ⋅ 1 = 0, and visually:

As expected, those vectors are linearly dependent. The angle formed by them is 0 degrees. Okay, but the system 4.22 has to have a solution because the determinant of A is not 0. To find it, let’s get the vector  represented by:
represented by:

The only thing missing is the vector  . Now,
. Now,  is not as badass as
is not as badass as  because,
because,  can take any value for coordinates. On the other hand,
can take any value for coordinates. On the other hand,  has fewer options, much like a politician:
has fewer options, much like a politician:

The equation below represents the system in question:

Let’s pause for a moment to observe the representation above, that is if you don’t mind. A is a matrix that represents a linear transformation, and  is a vector. We know that A.
is a vector. We know that A. will map
will map  into a new vector. The restriction now is that the resultant recast vector of that transformation has to be equal to another vector,
into a new vector. The restriction now is that the resultant recast vector of that transformation has to be equal to another vector,  :
:

The plot is populated, but let’s take it step-by-step. The vectors  and
and  represent the standard basis. A generic vector is represented by
represent the standard basis. A generic vector is represented by  , so please ignore the coordinates (2, 4). It is just for a visual representation. Now,
, so please ignore the coordinates (2, 4). It is just for a visual representation. Now,  and
and  are the new basis as they are the result of the transformation of A on
are the new basis as they are the result of the transformation of A on  and
and  . The vector
. The vector  is where we need
is where we need  to land. There are several ways to get the solution for that system, we will focus our attention on a technique called the Cramer’s rule. As while it may not be the most efficient approach, it is the method with the best visual component. In this case, best means efficient in terms of computation. Our goal is not to learn how to calculate these solutions by hand. We have computers to do that. Instead, we just want to understand what is happening so we can better analyse the results.
to land. There are several ways to get the solution for that system, we will focus our attention on a technique called the Cramer’s rule. As while it may not be the most efficient approach, it is the method with the best visual component. In this case, best means efficient in terms of computation. Our goal is not to learn how to calculate these solutions by hand. We have computers to do that. Instead, we just want to understand what is happening so we can better analyse the results.
Let’s start by grabbing three elements from the plot above: the basis formed by the vectors  and
and  , and the generic vector
, and the generic vector  . Consider the following plot:
. Consider the following plot:

The vector  represents any vector that verifies a system of equations; its coordinates are (x1,x2). In this case, the blue parallelogram has an area equal to 1.x2, meaning that the value of this area is equal to x2. Let’s be rigorous here; it is not the area, but rather the signed area, because x2 can be negative. We can make a similar case with the other coordinate in
represents any vector that verifies a system of equations; its coordinates are (x1,x2). In this case, the blue parallelogram has an area equal to 1.x2, meaning that the value of this area is equal to x2. Let’s be rigorous here; it is not the area, but rather the signed area, because x2 can be negative. We can make a similar case with the other coordinate in  , a parallelogram with an area of x1 instead of x2:
, a parallelogram with an area of x1 instead of x2:

The signed area of the blue parallelogram will be 1.x1, resulting in x1. These parallelograms can also be built with the transformed versions of  ,
,  and
and  . Let’s start with the vector
. Let’s start with the vector  that has coordinates (−5,−4). But instead of
that has coordinates (−5,−4). But instead of  , we have
, we have  , which is the result of transforming
, which is the result of transforming  with A:
with A:

In the plots 4.22 and 4.23, we drew two different parallelograms. One with the vector  and
and  , and the other formed by
, and the other formed by  and
and  . These have areas values of x2 and x1 respectively. Following this, we transformed
. These have areas values of x2 and x1 respectively. Following this, we transformed  and
and  to obtain a new parallelogram which we don’t yet know the area of (as shown in the figure above). In order to derive x2, one must find some relationship between the areas of the original and transformed parallelograms. Fortunately, we have a scalar that provides information relating to the magnitudes by which sizes are scaled via linear functions. So, if the area of the original parallelogram was x2, this new shape will have an area of det(A) ⋅ x2:
to obtain a new parallelogram which we don’t yet know the area of (as shown in the figure above). In order to derive x2, one must find some relationship between the areas of the original and transformed parallelograms. Fortunately, we have a scalar that provides information relating to the magnitudes by which sizes are scaled via linear functions. So, if the area of the original parallelogram was x2, this new shape will have an area of det(A) ⋅ x2:


We know the coordinates of vector  and we know where it lands, so we can create a new matrix:
and we know where it lands, so we can create a new matrix:

The determinant of this matrix will represent the area of the transformed parallelogram:

If we want to derive a formula to compute x1 it is done in the same way as was shown for x2. The only difference is that we will transform the vector  and use its transformed version alongside
and use its transformed version alongside  to build the new parallelogram:
to build the new parallelogram:


We know the coordinates of vector  , so:
, so:

We have found that the solution for our system is the vector  = (2, 4)T. Indeed there are computers that can tally all of these tedious calculations, almost like having slaves without any feelings. I wonder what will happen if they ever get to the point of sentience. Will they miraculously channel all of their pain into the creation of new styles of dance and music that we can enjoy, even after the way we have treated them? Or will it be judgement day, and someone, John Connor style, will have to save us? I hope I haven’t lost you because you’re too young to have seen The Terminator? All the same, this technique is here to help you visualise what is happening. And, if you do choose to use a computer to solve a system, you won’t think that these black boxes are performing magic. Also, this showcases a situation that often occurs in mathematics, in which there are several ways to solve the same problem. The task was to find a new vector that, when transformed, would land on a specific set of coordinates. The method for finding a solution was derived based on areas. Another way to solve a linear system is Gaussian elimination, which won’t be covered here, though if you wish to learn it, I will say that you will have no problems with it. There are still two things missing: we need the general formula for Cramer’s rule, and we should verify what happens when we transform the vector
= (2, 4)T. Indeed there are computers that can tally all of these tedious calculations, almost like having slaves without any feelings. I wonder what will happen if they ever get to the point of sentience. Will they miraculously channel all of their pain into the creation of new styles of dance and music that we can enjoy, even after the way we have treated them? Or will it be judgement day, and someone, John Connor style, will have to save us? I hope I haven’t lost you because you’re too young to have seen The Terminator? All the same, this technique is here to help you visualise what is happening. And, if you do choose to use a computer to solve a system, you won’t think that these black boxes are performing magic. Also, this showcases a situation that often occurs in mathematics, in which there are several ways to solve the same problem. The task was to find a new vector that, when transformed, would land on a specific set of coordinates. The method for finding a solution was derived based on areas. Another way to solve a linear system is Gaussian elimination, which won’t be covered here, though if you wish to learn it, I will say that you will have no problems with it. There are still two things missing: we need the general formula for Cramer’s rule, and we should verify what happens when we transform the vector  with the linear transformation A. First things first, Cramer’s rule. Consider a linear system represented as follows:
with the linear transformation A. First things first, Cramer’s rule. Consider a linear system represented as follows:

Where A is a squared matrix with size n × n,  = (x1,x2,…,xn)T and
= (x1,x2,…,xn)T and  = (b1,b2,…,bn). We can then define the values of the vector
= (b1,b2,…,bn). We can then define the values of the vector  by:
by:

The value det(Ai) is the matrix formed by replacing the ith column of A with the column vector  . Next, for the verification part, we have to transform (2, 4)T with A and to check if we get
. Next, for the verification part, we have to transform (2, 4)T with A and to check if we get  :
:


Linear systems have many applications, but for now, I would like to explore four particular types of systems with some important characteristics. Consider a matrix Am×n that maps vectors from ℝn to vectors in ℝm. Let’s also define two vectors,  and
and  . The different systems that are worth paying special attention to are:
. The different systems that are worth paying special attention to are:
- A ⋅
 ≠0 row space of A.
≠0 row space of A. - A ⋅
 = 0 nullspace of A.
= 0 nullspace of A. - AT ⋅
 ≠0 column space of A.
≠0 column space of A. - AT ⋅
 = 0 left nullspace of A.
= 0 left nullspace of A.
The equations above define important subspaces in the field of linear algebra. A subspace is a space within another vector space where all the rules and definitions of vector spaces still apply. In case one, we are performing row-wise dot products with a vector  , and our interest lies in the calculations performed between rows that are not perpendicular, so that the result is not zero. This subspace is called the row space. On the other hand, in equation number two, we want a subspace where every vector is transformed to zero. This is called the nullspace. Finally, cases three and four represent very similar concepts, but as we are now computing dot products with the transpose of A, these subspaces are for the columns instead of the rows. So, case three is the row space, while case four is the left nullspace. There must be a relationship between the dimension of the space spanned by A and the subspaces that are part of A, namely those defined by the four systems shown above. To understand these relationships, we need to introduce another concept: rank. The rank of a matrix is the dimension of the vector space generated by its columns, meaning that it is also the basis of the column’s space. Let’s consider a matrix A4×3 defined as:
, and our interest lies in the calculations performed between rows that are not perpendicular, so that the result is not zero. This subspace is called the row space. On the other hand, in equation number two, we want a subspace where every vector is transformed to zero. This is called the nullspace. Finally, cases three and four represent very similar concepts, but as we are now computing dot products with the transpose of A, these subspaces are for the columns instead of the rows. So, case three is the row space, while case four is the left nullspace. There must be a relationship between the dimension of the space spanned by A and the subspaces that are part of A, namely those defined by the four systems shown above. To understand these relationships, we need to introduce another concept: rank. The rank of a matrix is the dimension of the vector space generated by its columns, meaning that it is also the basis of the column’s space. Let’s consider a matrix A4×3 defined as:

To calculate the rank of A, we need to understand how many linearly independent columns exist in matrix A. This quantity will also give the number that defines the dimension of the column space. After a closer look, we can identify that the first column is half of the second, and there is no way of getting the third column by combining the first two, or by scaling any of them. So the matrix has a rank equal to two. There are two linearly independent vectors, (1, 1, 2, 3) and (0, 1,−1, 0), and they form a basis for the column space. Now, let’s compute the nullspace of A. This space is such that {x ∈ ℝ3 : A. =
=  }. We are looking for all of the values of
}. We are looking for all of the values of  in ℝ3 , when transformed by A, result in the null vector, which is equivalent to:
in ℝ3 , when transformed by A, result in the null vector, which is equivalent to:

So it follows that:

I am about to drop some more notation so brace yourselves. The nullspace is represented by:

And in this particular case, it can also be represented by:

The dimension of the nullspace, which is also called the nullity(A), is equal to one, meaning that the basis of that space has only one vector. At this point, we have the dimensions of the column space and the nullspace: two and one respectively. Coincidentally or not, the dimension of the column space, which is equivalent to the rank of A plus the dimension of the nullspace, is equal to the number of columns in A. Obviously this is not a coincidence at all; the theorem of rank-nullity states that:
 |
(4.23) |
The proof of this theorem is extensive, and I will omit it, but what we can take from it will be extremely useful. The rank of A plus its nullity equals n, the number of columns. Apologies, but we must introduce another simple definition at this time, for the term full rank. A matrix A of size m × n is said to be of full rank when the rank is equal to the min(m,n). There are two possibilities to consider: m ≥ n and m < n. But why would we care about this? Well, it just so happens that we can understand the dimension of the nullspace when a matrix is of full rank by just looking at the order of magnitude of m and n. If A is of full rank and m < n, the rank of A is equal to m. By equation 4.23, we have m + nullity(A) = n, which is the same as:

On the other hand, if m ≥ n, it follows that the rank of A is equal to n, so the nullspace has a dimension of 0:

If the matrix is square, then n = m, so it makes sense that a square matrix is of full rank when the rank of A is equal to n. There are a couple more relationships between the nullity, the rank, and the determinant that are worth studying. Let A be such that:

Where all the vectors  are the columns of A. With this, the equation for nullity can be expressed by:
are the columns of A. With this, the equation for nullity can be expressed by:

Which is the same as:
 |
(4.24) |
If we say that all the vectors are linearly independent, the only way for equation 4.24 to be verified is for all of the factors represented by the x’s to be equal to 0. Otherwise, it will be possible to get at least one term as a function of another; consequently, the assumption of linear independence won’t be valid. Therefore, if the nullspace is of dimension zero, it also means that the determinant is non-zero. As you can see, the rank provides a lot of information about linear transformations and is an excellent way of exploring some of their characteristics.
When introducing the rank and deducing its relationships and properties, we paid a lot of attention to the nullspace of a matrix. This space is also essential when it comes to introducing one more notion, the last one before we vault into the concepts that are often used in machine learning: the principal component analysis and the single value decomposition.
Even though we are already well-equipped in terms of linear algebra knowledge, the feeling in the air is that everything really starts here. Let’s initiate this new part of the odyssey by defining a particular case of a linear system. What if we wish to find a vector  that, when transformed by A, lands on
that, when transformed by A, lands on  or on a scaled version of it? Before, we were looking for a vector
or on a scaled version of it? Before, we were looking for a vector  that, when transformed, would land on a generic vector
that, when transformed, would land on a generic vector  . We can define a scaling factor by λ and formulate the system with the following equation:
. We can define a scaling factor by λ and formulate the system with the following equation:
 |
(4.25) |
4.3.1 Line Up Vectors! The Eigen Stuff
Good people of the sun, allow me to introduce you to the Eigen ”stuff”. These vectors  that, when transformed by a matrix, land on itself or on a scaled version of itself are called the eigenvectors. They happen to be like the police as they are always with someone else, so for each eigenvector, you will have a corresponding eigenvalue λ, the scalar by which the vector stretches or shrinks. To put it simply, think of a matrix as a machine that rotates and/or scales vectors. An eigenvector is a vector that, when put through this machine, only gets stretched or shrunk by a certain amount but does not get rotated:
that, when transformed by a matrix, land on itself or on a scaled version of itself are called the eigenvectors. They happen to be like the police as they are always with someone else, so for each eigenvector, you will have a corresponding eigenvalue λ, the scalar by which the vector stretches or shrinks. To put it simply, think of a matrix as a machine that rotates and/or scales vectors. An eigenvector is a vector that, when put through this machine, only gets stretched or shrunk by a certain amount but does not get rotated:

In the plot above,  ,
,  represent the transformed version of the standard basis
represent the transformed version of the standard basis  ,
,  . We are looking for one or more vectors that, when modified by A, land on a linear combination of
. We are looking for one or more vectors that, when modified by A, land on a linear combination of  :
:

We have a few examples of eigenvectors in the plot above, and, as they are all linear combinations of each other, they all land on the black line that represents that particular vector span. Let’s manipulate equation 4.25 to get it into a format where the computation of both the eigenvectors and eigenvalues will be more straightforward. It is hard to find a good use case for manipulation. However, perpetrating this act to produce an equation still seems to be accepted. So far, nobody seems to care, and it comes with benefits for the mathematician. Let’s exploit this:

We’ve learned about the identity matrix on our journey into linear algebra, and so we can say:

Multiplying the identity matrix I by a given vector  will result in the vector
will result in the vector  . That equation is equivalent to:
. That equation is equivalent to:

We can then write it as:
 |
(4.26) |
There are two ways for 4.26 to be verified. The first one is not very interesting (the trivial solution). This is when  = 0. That told us nothing, so we need to find a
= 0. That told us nothing, so we need to find a  other then
other then  = 0. The element (A−λI) is a matrix whose diagonal elements are part of the diagonal of A minus the scalar λ, something like:
= 0. The element (A−λI) is a matrix whose diagonal elements are part of the diagonal of A minus the scalar λ, something like:

So, equation 4.26 can be depicted as:
 |
(4.27) |
Ideally, we would have an equation where we can apply some technique and calculate the λ′s. If you recall, the determinant is a function that takes in a matrix and spits out a scalar, and we have a formula for it, so this might be an excellent path to follow to find an equation where we can isolate λ. However, the determinant alone won’t be enough to get us to where we need to be. That zero on the right side of the equation causes constraints, and we need to consider them. Thankfully, there is a way to create a relationship between the determinant and zero. For example, consider the inverse of a matrix. For a matrix to have an inverse, its determinant has to be non-zero. In addition, it comes to mind that, if a matrix is invertible, the multiplication of this given matrix with its inverse results in the Identity matrix. Maybe we can work with this. Let’s define the inverse of R by R−1 and replace this notation with 4.27:

This results in:

And that is as valuable as an ashtray on a motorbike. We specifically stated that  = 0 was not of interest. But everything’s not lost. What follows is that R must not be invertible, and like that, we guarantee any non-trivial solution! So, if R has no inverse, the determinant of that specimen must be zero:
= 0 was not of interest. But everything’s not lost. What follows is that R must not be invertible, and like that, we guarantee any non-trivial solution! So, if R has no inverse, the determinant of that specimen must be zero:

Geometrically, this also makes sense. We are transforming a vector  into a linear combination of itself. For that, the determinant has to be zero, as we saw previously. Let’s follow an example and use A as the linear transformation:
into a linear combination of itself. For that, the determinant has to be zero, as we saw previously. Let’s follow an example and use A as the linear transformation:

This is equivalent to:



From our fundamental maths knowledge we know that the roots for that equation can be calculated with the following formula:

Where:

Okay, so applying that formula to our equation gives us the following values for λ:

We now have the scaling values that will stretch or squish the eigenvectors, but we still do not have the vectors. However, there is a formula that allows us to get these vectors: 4.26:

Given that we know the λ values, we can compute the eigenvectors. Let’s try with λ = −3.


Let’s name that guy. Should we go for Francis? Maybe it is too much, but M should be enough:

This represents a linear system, but the determinant of the matrix M is zero. Does this make sense? A determinant of 0? This means that we either have no solutions, or a lot of them. The latter is happening here. The coordinate values that verify that the system can be represented by vectors that land on the span of the vector that we are after. There is an implication to this determinant value; Cramer’s rule will be doing a prophylactic isolation and can’t show up. The system becomes:

This is a simple system that is here as a showcase, therefore we can solve it with a ”maneuver” like this:


So, the eigenvector corresponding to the eigenvalue λ = −3 is the vector (1, 1)T, let’s call it  :
:

If we transform  with A,
with A,  , the transformed version of
, the transformed version of  needs to land on that black line. It has to be the vector (−3,−3)T; let’s verify this:
needs to land on that black line. It has to be the vector (−3,−3)T; let’s verify this:


Okay, that verifies the calculations. If we do something similar to that with λ = −3, but now with the other eigenvalue, λ = −1, we end up with:


I will omit some of the steps of the calculations as they are like the ones that we did for the other eigenvalue, but this time, the eigenvector is equal to  = (
= ( , 1)T. Similarly, if we transform
, 1)T. Similarly, if we transform  into
into  making use of the linear transformation A,
making use of the linear transformation A,  has to land on the same line as
has to land on the same line as  . Let’s verify:
. Let’s verify:

As expected, the resultant vector is a linear combination of the original vector that we transformed with the matrix A. Let’s visualise this result:

In essence, we found a particular group of vectors that, when transformed, land on its span. If you are doubtful about the utility of this concept, I empathise with that, but allow me to try to convince you that this was not an attempt to put a few more pages in this book so that it gets to at least 100 pages! So, let’s bring back the 90’s! Sorry, I mean matrix A, its eigenvalues, and the respective eigenvectors:


As a friendly reminder, this is how we can represent the system to calculate the eigenvalues:

Okay, if we now replace  and λ with each eigenvalue and eigenvector pair, we can form two different equations:
and λ with each eigenvalue and eigenvector pair, we can form two different equations:
 |
(4.28) |
So, we have two vector equations. By forming one matrix with the eigenvectors and another with the eigenvalues, we can combine the two equations in 4.28 into a single equation with matrices:

Algebraically we have:
 |
(4.29) |
When we studied the inverse of a matrix, we concluded that for a matrix A−1 to be the inverse of A, AA−1 = I. So, if we want to isolate A on the left side of equation 4.29, we can multiply both sides of the equation by P−1:

Which becomes:
 |
(4.30) |
4.3.2 I’ve Got the Power, to Power – Matrix Diagonalization
So, we can define A as a product of three other matrices, including the eigen base P and its inverse P−1 which represent two rotations. On the other hand, the matrix Λ is a diagonal matrix with eigenvalues for elements. On this matrix are the scaling terms of equation 4.30. So, what’s happening here is that we are representing a matrix by two rotations and one scaling term. Since we have a linear transformation that is split into three different matrices, it is worth taking a look at the properties of these matrices.
One of them stands out: Λ, which is a diagonal matrix. The only time we dealt with a matrix of this type was when the identity I was involved in our calculations. It turns out that this class of matrices, the diagonal ones, has some pretty incredible properties that make operations much lighter and more manageable. For example, to calculate the determinant of a matrix with this form, one only needs to multiply the elements that form the diagonal. Let’s consider A to be a diagonal matrix defined as:

By definition, the determinant of A is:

A has two dimensions, and these are always simple cases. However, if we have matrices of higher dimensionality, the calculations for the determinant are now more straightforward than the ones for non-diagonal matrices. Let’s now consider a matrix A with three dimensions:

We know that we can pick a row or a column and apply the Laplace expansion that we previously defined to calculate the determinant. If you don’t remember, there is no need to feel bad or even go look for it. Here it is again:

As you can see, in this formula, an element of the matrix is multiplied by a minor, aij. As this is a diagonal matrix, the only non-zero elements are those on the diagonal when j = i, so the determinant will simply be:

This is the same as multiplying all of the elements on the diagonal together. It is fair to assume that if we can simplify the calculation of the determinant for a diagonal matrix, then the computation of its inverse will also have a more straightforward formula, and it does! Previously we specified that:

If we have all the 0 entries excluding the diagonal, the matrix adj(A), is equal to:

This is equivalent to:

And if we divide that adj(A) by the determinant:

This results in:

This simplifies the calculation of an inverse. So, we have to replace each non-zero element with its inverse. The last thing to mention about diagonal matrices relates to a scenario in which we want to compute multiplications. Let’s define a generic 2 × 2 matrix X as:

There are two different scenarios here: The first, matrix multiplication, is not commutative; however, if one of the matrices in the operation is diagonal, we can easily get the results. If X is multiplied by a diagonal on the left, it will change the matrix row-wise. Otherwise, if we are multiplying X by a diagonal matrix on the right, then this will have an impact column-wise. This will apply to any matrix size.


Secondly, and this will be the most potent fact about this diagonalization technique, we can simplify the multiplication between matrices. As the non-zero elements are all on the diagonal, powering these matrices comes with comfort, as it will only be necessary to power each component of the diagonal. Just to explain, when we say powering, we’re referring to the process of multiplying a matrix by itself, which is the same as raising it by a power.
Okay, the reality is that two-by-two matrices are baby talk. They make clear-cut examples, but when do we have the opportunity to work with only two dimensions in the real world? If you wish to go on with machine learning, you will most likely encounter some big ass matrices, and on top of that, consider the fact that you have to power them with a large exponent. Diagonalization will then come in handy to save the day and the computation bill! We know that A can be represented by:

Say that A is a n × n matrix where n is giant (no joke). Think of a matrix with information about the weather, like states of observable climate conditions, where the matrix entries are probabilities of moving from one state to another. You could model this with some type of sequential model where the states are the weather conditions on a given day. An example of this type of model is a Markov Chain (which we won’t go into right now, but it will be covered on a different book). Under these conditions, there is a case for powering a matrix because it will allow you to understand the system at a given state. So, powering A to the t (where t is large) can be computed by multiplying A by itself t times, which is extremely expensive in terms of computation time . Imagine all the dot products that we’d have to do. But don’t worry, we can make use of matrix diagonalization: instead of…

…we could try and do something different. Let’s start by squaring A:
 |
(4.31) |
A was replaced by its diagonalization form, and we can simplify equation 4.31, as we know that P ⋅ P−1 is equal to the identity I:

The matrix Λ is diagonal, so it follows that Λ.Λ is equal to Λ2 and the equation becomes:

Right, this seems simpler to compute. Let’s check what we can do if we have A3. Well, A3 = A2.A, which can be written thus:

Following the same logic as before:

Let’s check for A4… I am joking, but you see where this is going. If you want to power A to t, the formula is:

Powering matrices is a common practice in machine learning. You probably won’t have to write code for it. But still, I can assure you that when you are applying algorithms to data, it is likely that at some point, it will happen. Suppose we try to interpret the equation for diagonalization geometrically. In that case, we see that we can represent a linear transformation as one rotation, followed by a stretch, and then another rotation. Let’s experiment: For that we’ll need a volunteer, anyone? Anyone at all? Mr.  , welcome back, sir. Firstly we will transform it with A. Following this, we will take a longer route, going from P−1 to Λ, and finally to P. Okay,
, welcome back, sir. Firstly we will transform it with A. Following this, we will take a longer route, going from P−1 to Λ, and finally to P. Okay,  has the coordinates (1, 3)T, and when mapped by A it results in:
has the coordinates (1, 3)T, and when mapped by A it results in:

The plot bellow illustrates the transformation A on  , which we represent with
, which we represent with  :
:

 needs to go.
needs to go.Let’s now check what happens if we rotate, stretch and rotate again the vector  with PΛP−1. The result has to be a vector with coordinates (1,−1)T. There is one thing missing. Well, it is more like three; the dam matrices. We have calculated the eigenvectors of A, so we are good in regards to P. It is a matrix with the eigenvectors of A for columns. Now Λ is even more accessible. It is a matrix whose diagonal has for entries the eigenvalues of A, and the remaining entries are 0. That fellow P−1 is the inverse of P, and we already know how to invert a matrix, so we are in no danger of being stuck. With this, we are ready to start, so bring on the first rotation, please, maestro:
with PΛP−1. The result has to be a vector with coordinates (1,−1)T. There is one thing missing. Well, it is more like three; the dam matrices. We have calculated the eigenvectors of A, so we are good in regards to P. It is a matrix with the eigenvectors of A for columns. Now Λ is even more accessible. It is a matrix whose diagonal has for entries the eigenvalues of A, and the remaining entries are 0. That fellow P−1 is the inverse of P, and we already know how to invert a matrix, so we are in no danger of being stuck. With this, we are ready to start, so bring on the first rotation, please, maestro:

Now, let’s scale it:

Finally, let’s rotate it again:

When we rotate  with P−1 we end up with a transformed vector
with P−1 we end up with a transformed vector  that is then stretched by λ into a new vector called
that is then stretched by λ into a new vector called  . This is then rotated by P to result in
. This is then rotated by P to result in  which in turn, has the same coordinates as
which in turn, has the same coordinates as  . There is another name for this diagonalization technique. It is also known as eigendecomposition, which is a special case of matrix decomposition:
. There is another name for this diagonalization technique. It is also known as eigendecomposition, which is a special case of matrix decomposition:

 .
.The only catch is that the matrix that we decompose has to be square. Otherwise, we can’t use this technique. Unfortunately, square matrices are as standard as tax rebates, which means they rarely come by, and, if you do come across one, it is likely you messed up somewhere. Don’t worry, it happens. So, if square matrices are not that common, there’s got to be a way to decompose any matrix shape. And there is. You can refer to it as the single value decomposition, or by its street name, SVD. These techniques of splitting a matrix into a multiplication of newly created matrices with particular characteristics have great visual interpretations. When it comes to introducing this new form for decomposing a matrix, we will focus on that.